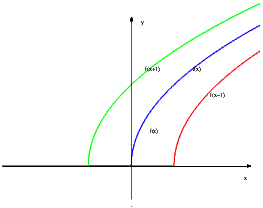
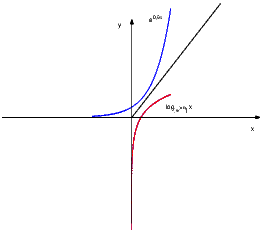
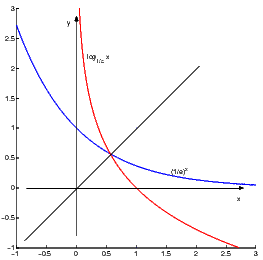
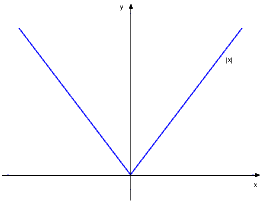
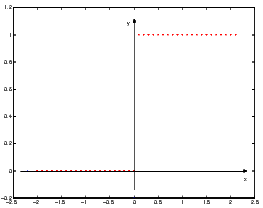
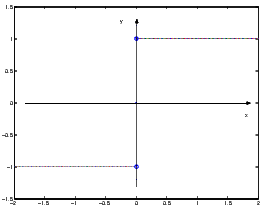
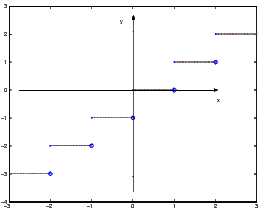
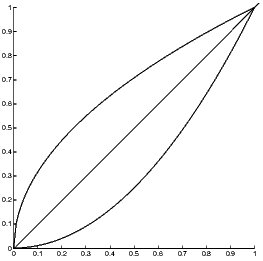
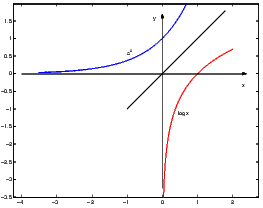
lim nn = 1
2.2 La continuità
Abbiamo bisogno della definizione seguente:
Definizione 70 Sia .
Si dice che
è punto isolato di
quando esiste in intorno
tale che .
Dunque, ogni punto isolato di
è un punto di
e inoltre un punto non può essere contemporaneamente isolato e di accumulazione per
. Per
esempio,
è punto isolato (e quindi non di accumulazione) di
. Veniamo ora
alla definizione di continuità. Per poter parlare di continuità di una funzione in un punto
è necessario che
appartenga al dominio
della funzione.
Sia quindi
una funzione il cui dominio contiene un punto
.
Definizione 71 la funzione
è continua in
quando si verifica uno dei due casi seguenti:
- il punto
è punto isolato di .
- il punto
è punto di accumulazione per ,
esiste
ed inoltre
Si dice che è continua da destra
in quando è
continua la funzione .
Analoga definizione per la continuità da sinistra
Osservazione 72 La scelta di definire “continua” una funzione nei punti
isolati del dominio può sembrare bizzarra. Ne vedremo tra poco l’utilità.
Notiamo però subito una conseguenza: ogni successione è continua in ciascun
punto del suo dominio.
La definizione di continuità può darsi in modo “unificato” come segue:
è continua
in
quando
Questa sembra la definizione di limite, ma
non è così: non abbiamo richiesto che
sia punto di accumulazione di ;
e, se
è punto isolato, l’unico punto di
che verifica
è, per
abbastanza piccolo, il solo punto .
Notare che la definizione di limite richiede anche di imporre
,
condizione che nel contesto della definizione
di continuità si può omettere perché
è automaticamente minore di ,
che è positivo. Dunque, se
è punto di accumulazione di
allora
è continua in
se e solo se
Vale il teorema seguente:
Teorema 73 Siano e
due funzioni continue
in . Le funzioni seguenti
sono continue in :
Se , è continua
in anche
la funzione .
Dim. Esaminiamo il caso della somma: se
è punto isolato per il
dominio di allora questa
funzione è continua in .
Altrimenti, è punto di
accumulazione per il dominio
e per la restrizione a sia
della prima funzione
che di .
Dunque i teoremi sui limiti mostrano che
Osservazione 74 Si noti che può darsi che
sia punto di accumulazione sia di
che di
ma non del dominio della somma. Si consideri l’esempio
Ambedue le funzioni sono continue in ,
con
punto di accumulazione dei domini, ma la funzione somma
è definita nel solo punto .
Se non si definisce “continua” una funzione nei punti isolati del dominio, non
si può affermare che la somma di funzioni continue è continua. Questa è la
ragione per cui abbiamo dato la definizione 71.
In modo analogo si provano anche i risultati seguenti:
Teorema 75 Sia .
La funzione
è continua in
se e solo se è continua sia da destra che da sinistra in .
Teorema 76 (limitatezza locale e permanenza del segno) Se
è continua
in
allora:
Dim. La funzione
è continua in
quando per ogni
esiste tale che
ogni , incluso
il punto ,
si ha
L’asserto relativo alla limitatezza locale segue scegliedo, per esempio,
.
L’asserto relativo alla permanenza del segno si ottiene (quando
) scegliendo per esempio
. con questa scelta, si
trova un intorno di
su cui vale : il
numero cercato è
.
Osservazione 77 Si noti la differenza di quest’enunciato da quello del
teorema relativo ai limiti di funzioni, che potrebbero essere discontinue in
.
Se
non è continua in ,
la conoscenza del limite niente permette di concludere sul segno di .
Infine:
Definizione 78 Una funzione continua in ciascun punto di un insieme
si dice “continua su ”.
Se ,
la funzione si dice “continua sul suo dominio” o anche semplicemente
“continua”. Per dire che
è continua su un insieme
si scrive
o talvolta .
2.2.1 Classificazione delle discontinuità
Sia definita
in , ma non
continua. Il punto
si dice:
Il termine “discontinuità eliminabile” (o discontinuità rimuovibile) si
spiega da solo: cambiando la definizione della funzione nel solo punto
, e
ridefinendo
si trova una funzione continua.
Non si esclude che uno dei due limiti possa coincidere col valore della funzione; ossia
che la funzione sia continua o da destra o da sinistra.
- ogni altro caso di discontinuità si chiama
discontinuità di seconda specie
Infine, consideriamo una funzione
che non è definita in .
Supponiamo però che esista finito
In questo caso, la funzione
è continua: è l’unica estensione per continuità di
ad
.
Osservazione 79 Se
è un punto di accumulazione per ,
l’estensione per continuità di
ad
se esite è unica, ma possono esitere estensioni per continuità non uniche ad
insiemi più grandi. Per esempio
La funzione
ammette infinite estensioni continue ad ,
ma tutte assumono il valore
in .
Se si vuole l’estensione continua a
questa è unica.
2.2.2 Continuità di alcune funzioni importanti
Sono continue le funzioni della lista seguente, ovviamente nei punti in cui sono
definite:
- i polinomi;
- le potenze
con
reale qualsiasi;
- le funzioni razionali;
- la funzione ;
- le funzioni goniometriche:
,
,
e ;
- la funzione logaritmo, ,
per ogni base
(positiva e diversa da );
- la funzione esponenziale
per ogni base .
Vediamo in particolare come si tratta il caso delle funzioni goniometriche.
Limiti e continuità di funzioni goniometriche
Ricordiamo che gli angoli si misurano in radianti, ossia che la
misura dell’angolo al centro di una circonferenza di raggio
è uguale
alla lunghezza dell’arco che l’angolo identifica sulla circonferenza. Proviamo
che per :
- si ha: ;
- si ha: .
Le funzioni ,
e
sono dispari e quindi basta provare le disuguaglianze per
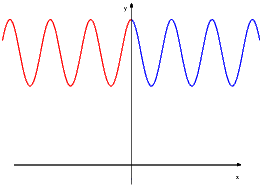
. La figura 2.4 illustra
la definizione di e
: la circonferenza ha
raggio e l’angolo al
centro ha misura ,
ossia
è la lunghezza dell’arco che congiunge i punti
ad
, disegnato rosso. In tal
caso, è la lunghezza
del segmento ,
disegnato rosso e è la
lunghezza del segmento ,
disegnato fucsia.
Si sa che in una circonferenza un arco è più lungo del segmento che ne congiunge gli estremi: l’arco
che congiunge ed
è più lungo del
segmento , ossia
dividendo per
|
| (2.10) |
Il settore circolare è
contenuto nel triangolo rettangolo
e quindi ha area più piccola. Calcolando le aree si trova
ossia, |
| (2.11) |
Conseguenza di queste disuguaglianze: la funzione
è continua
per .
Infatti, il teorema del confronto applicato a
mostra che
Combinando questo con le formule di prostaferesi |
|
segue che le funzioni
e
sono continue. Infatti per sempio si ha
e, per il teorema del confronto, .
In particolare, |
| (2.12) |
Dunque anche le funzioni
e
sono continue. Proviamo ora che
La funzione
è pari e quindi basta calcolarne il limite destro per
tendente
a .
Le disuguaglianze (2.10) e (2.11) implicano (ricordiamo che si lavora per
)
Dividendo per
si trova
Usando (2.12), il teorema di confronto implica che
2.3 Limiti di funzioni composte
Siano e
due funzioni
tali che
cosìche si può calcolare la funzione composta
.
Supponiamo inoltre che sia |
| (2.13) |
Ci si può chiedere se sia vero che |
| (2.14) |
La risposta è in generale negativa. E’ positiva se si impongono ulteriori
condizioni. Vale infatti:
Teorema 80 Sia
punto di accumulazione per il dominio della funzione composta .
Sia
e valga
Supponiamo inoltre che valga una delle tre condizioni seguenti:
-
sia continua (e quindi definita) in ;
-
non prenda il valore ;
- la funzione
non sia definita il .
Allora si ha
Osservazione 81 Il teorema precedente vale anche se
e vale anche se uno o ambedue i limiti
e
sono .
Se però
allora la condizione che
non prenda il valore
non può eliminarsi. Infatti, senza questa condizione può essere che il limite
della funzione composta esista ma diverso da quello di
oppure che non esista, come provano i due esempi seguenti. In ambedue gli
esempi,
Consideriamo ora i due esempi:
Esempio 1) sia .
La funzione
è
Per ogni
si ha
In quest’esempio, il limite della funzione composta esiste, diverso da quello di
.
Esempio 2) E’ ancora
ma la funzione
è
La funzione è
priva di limite per .
Infatti, il limite non può essere nè positivo nè negativo per il teorema di
permanenza del segno, dato che la funzione si annulla in ogni intorno di
(infatti si annulla quando
). E però il limite non può
essere perchè la funzione
prende valore in ogni intorno di
.
Corollario importante del teorema 80 è:
Corollario 82 Una funzione composta di funzioni continue è continua.
Quando è continua
nel punto ,
l’asserto del teorema 80, ossia
può scriversi |
| (2.15) |
Ossia, se è continua
in , il simbolo di
si scambia col simbolo
della funzione .
L’esempio seguente mostra che l’uguaglianza (2.15) è falsa se la funzione
non è
continua in .
Esempio 3) Sia
(la parte intera di )
e sia . Si consideri
il limite per . In
un intorno di si
ha che prende
valore tra ed
, ed il valore
viene assunto
solamente per .
Inoltre
Dunque, per in
un intorno di ,
escluso ,
Di conseguenza,
Illustriamo ora l’uso di questi risultati, che è sia “in positivo”, per garantire la
continuità e l’esistenza di limiti, che “in negativo”, per verificare che certi limiti
non esistono.
2.3.1 Le sottosuccessioni e i loro limiti
Sia una successione
e sia una successione
a valori nei numeri naturali. In questo caso è possibile considerare la funzione composta
, che è ancora una
successione, di indice .
“Successioni composte” definite in modo cosígenerale hanno poco interesse. E’
invece importante il caso in cui la successione
In questo caso la successione composta si chiama sottosuccessione di
(si dice anche che è una “successione estratta” da
) e si
indica col simbolo
Il teorema delle funzioni composte implica che:
Teorema 83 Se
allora si ha anche
per ogni sottosuccessione di .
Osserviamo che si potrebbe anche far vedere che vale il viceversa: si ha
se e solo
se per ogni
sottosuccessione di .
2.3.2 Risultati “in positivo”: calcolo di limiti per sostituzione
Come si è detto, la funzione composta di funzioni continue è continua. Quindi sono
funzioni continue in ciascun punto del loro dominio per esempio le funzioni della tabella 2.5
(nella quale
e
indicano generici polinomi).
Table 2.5: Esempi di funzioni composte
Le funzioni della tabella sono solo alcuni degli esempi di funzioni la
cui continuità segue immediatamente usando il Corollario 82. La tabella
va letta in questo modo. Consideriamo per esempio la prima funzione,
. La
funzione
è definita per
e prende valori
nel dominio di .
Dunque la funzione composta è definita per ogni
. Sia
che
sono funzioni
continue, e quindi
è una funzione continua. Consideriamo la seconda funzione,
. Appartengono al suo
dominio le sole per
le quali è positivo.
Ambedue le funzioni
e sono continue;
e quindi la funzione composta è continua. Guardiamo ancora la seconda funzione della tabella,
, ma questa volta
per . Il punto
non appartiene
al dominio di
ed è
Dunque, il Teorema 80 permette di affermare che
In certi casi, il teorema 80 permette di calcolare i limiti per sostituzione ossia sostituendo
alla variabile
una funzione invertibile ossia iniettiva e suriettiva
che semplifichi la funzione da studiare, tale che la sua funzione inversa
verifichi le ipotesi del teorema. Infatti, se
allora
Vediamo un esempio:
Esempio 84 Si voglia calcolare
La sostituzione
mostra che questo limite è uguale a
2.3.3 Risultati “in negativo”
Il Teorema 80 si può applicare quando in particolare la funzione più interna ha
dominio ,
ossia è una successione. In tal caso l’enunciato del teorema si riformula come
segue:
Teorema 85 Sia
(con i limiti
e
finiti o meno) e sia
per ogni .
Nel caso in cui
assumiamo che
sia continua in
oppure che
non sia uno dei valori della successione. Allora,
Questo teorema si usa più spesso “in negativo”: se si trovano due successioni
e
ambedue convergenti
ad (che non
prendono valore )
tali che
allora non esiste
(si confronti con quanto detto al paragrafo 2.1.5). Consideriamo ora la
funzione
Vogliamo provare che questa funzione non ammette limite per
. Per
questo consideriamo le due successioni cosìdefinite: |
|
Si noti che, essendo ,
si ha: ,
e
inoltre
Dunque,
In modo analogo si tratta il caso .
Queste osservazioni possono in particolare applicarsi per mostrare che non
esiste il limite di certe successioni. Per esempio, il limite della successione
non
esiste. Infatti consideriamo le due sottosuccessioni
La prima converge a mentre
la seconda converge ad
e quindi la successione
è priva di limite (si veda anche il Teorema 83).
Regole di calcolo e forme indeterminate di tipo esponenziale
Si voglia studiare il comportamento della funzione
Il modo più semplice per farlo consiste nello scrivere la funzione come
studiare il comportamento dell’esponente ed usare il teorema della funzione
composta. Per esempio, se
allora
Se però
e cosìnasce la forma indeterminata .
Analoga origine hanno le altre “regole” o “forme indeterminate” di tipo
esponenziale.
2.4 Le funzioni iperboliche
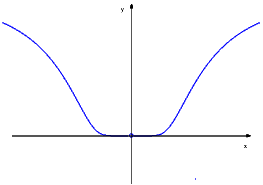
Si chiamano funzioni iperboliche la funzioni
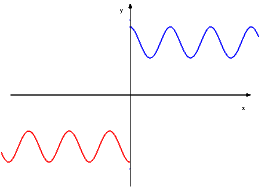
I grafici di queste funzioni sono riportati in figura 2.6, a sinistra.
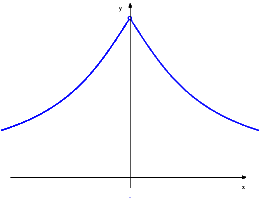
Si definiscono quindi le funzioni
I grafici sono in figura 2.6, a destra. Spieghiamo la ragione del termine “funzioni
iperboliche”. Le “funzioni circolari” sono le usuali funzioni goniometriche
e
.
Si chiamano “funzioni circolari” perché la coppia
verifica l’equazione della circonferenza
e, viceversa, ogni punto della circonferenza trigonometrica si rappresenta
come .
Le funzioni iperboliche hanno questo nome perché la coppia
verifica l’equazione dell’iperbole equilatera
e, viceversa, ogni punto di quest’iperbole ha coordinate
per un’opportuna
scelta di .
La verifica è immediata calcolando i quadrati di
e
e
sottraendo.
Questa formula va ricordata:
Dal punto di vista dei limiti, si ha:
|
|
|
| | | | | | | | | | |
| | | |
| | | | |
|
|
|
| | | | | |
| | | |
| | | | |
|
|
|
| | | | | |
| | | |
| | | | |
|
|
|
| | | | | |
| | | |
| | | | |
|
|
|
| | | | | |
| | | |
| | | | |
|
|
|
| | |
Dunque, le funzioni iperboliche sono continue. Le funzioni
e
sono
strettamente crescenti e quindi invertibili. Ammettono funzioni inverse che si
chiamano settore seno iperbolico e settore tangente iperbolica Le funzioni
e
sono strettamente
crescenti su .
Le funzioni inverse delle loro restrizioni a tale intervallo si chiamano settore coseno iperbolico
e settore cotangente iperbolica Queste quattro funzioni si indicano con i simboli
e
. I
grafici delle quattro funzioni inverse sono in figura 2.7.
2.5 Confronto di funzioni
In presenza di forme indeterminate, in particolare quando si debba calcolare il
limite di un quoziente, si cerca di individuare, se esistono, i “termini dominanti”,
come nei due esempi seguenti:
Esempio 86 Si voglia calcolare
E’ chiaro che per
“prossimo a ”
sia
che
saranno via via meno importanti rispetto ad .
Quindi scriveremo, per
e da qui si vede facilmente che
D’altra parte, sia da calcolare
In questo caso dominano a numeratore l’addendo
ed a denominatore l’addendo .
Quindi scriveremo
e quindi
Vogliamo introdurre delle definizioni che permettano di seguire quest’idea in casi più
generali di quelli dell’esempio precedente. Per questo si considerano due funzioni
e
(con lo stesso dominio).
Supponiamo inoltre
non zero. Si dice che
è o piccolo di
(per
tendente a )
se accade che
Come notazione, si scrive
Si noti che la notazione “”
non fa comparire .
La definizione riguarda il limite per
,
ma chi sia
va dedotto dal contesto. Ovviamente, in
un breve esercizio ciò sarà impossibile e
andrà esplicitamente specificato.
In questa definizione, non si richede che
oppure
siano infiniti o infinitesimi.
Per esempio, se ,
la notazione
Ossia, si scriverà
per scrivere che è
un infinitesimo per .
Però, a parte questo singolo caso, di regola l’uso del simbolo di Landau
“”
si incontra quando le due funzioni sono infiniti o infinitesimi per
, ossia
come si dice, sono infiniti o infinitesimi contemporanei. L’interpretazione del
significato del simbolo di Landau varia a seconda che si lavori con infiniti oppure
con infinitesimi. Infatti:
Siano
e
due infiniti per .
Allora, la condizione
intuitivamente significa che
diverge più lentamente di .
Per questo, quando
ed
e
sono infiniti si dice che
è infinito di ordine inferiore a
o che
è infinito di ordine superiore ad
(sottinteso: per ).
Invece:
Siano
e
due infinitesimi per .
Allora, la condizione
intuitivamente significa che
tende a zero più velocemente di
.
Per questo, quando
ed
e
sono infinitesimi si dice che
è infinitesimo di ordine superiore a
o che
è infinitesimo di ordine inferiore ad
(sottinteso: per ).
Per esercizio, passando ai reciproci, si riformulino le due proprietà appena esaminate
supponendo che .
Se accade che |
| (2.16) |
si dice che i due infiniti (o infinitesimi)
e
hanno lo
stesso ordine di grandezza (brevemente, diremo che “hanno lo stesso ordine”) per
e
scriveremo
Se il limite in (2.16) non esiste, si dice che i due infiniti o infinitesimi
e
non sono confrontabili
per . Se
invece il limite esiste, finito o meno, si dice che essi sono confrontabili Siano ancora
e
due infiniti oppure
due infinitesimi (per ).
Si dice che essi sono equivalenti se
In tal caso si scrive
al solito sottintendendo “per ”.
Dividendo i due membri per
e passando al limite, si vede che
Teorema 87 I due infiniti o infinitesimi contemporanei
e
sono equivalenti (per )
se e solo se
D’altra parte,
Dunque,
Corollario 88 Vale
se e solo se
e ciò accade se e solo se
Infine, può accadere che esistano numeri reali
e
con
e tali
che
In questo caso si dice che:
-
è un infinito oppure un infinitesimo di ordine
rispetto a ;
- la funzione
si chiama la parte principale di
rispetto a .
Osservazione 89 Va notato che due infinitesimi o infiniti possono essere
confrontabili, senza che esista l’ordine dell’uno rispetto all’altro, ossia senza
che esista la parte principale dell’uno rispetto all’altro. Per fare un esempio,
consideriamo le due funzioni
Si tratta di due infiniti per
e usando i risultati nella tabella 2.4 si vede che
Dunque i due infiniti sono confrontabili, e
è di ordine superiore rispetto ad .
Però, ancora dalla tabella 2.4, si vede che
Quindi, non esiste l’ordine di
rispett a
e dunque nemmeno la parte principale.
Simboli di Landau
I simboli ,
ed
si chiamano simboli di Landau dal nome del matematico tedesco che li
ha introdotti. Esistoni altri simboli di Landau. In particolare si dice che
è
O grande di
(per ) se
esiste ed
un intorno
di
tale che
Se ciò accade si scrive
Si noti un caso particolare: se esiste finito
allora (in un
opportuno intorno di ).
Infine, un’osservazione sul significato del simbolo
. Di questo
abbiamo dato una definizione assai particolare. Specialmente in testi di fisica, si scrive
quando
esistono
ed
tali che
almeno in un intorno di un sottinteso
,
senza richiedere l’esistenza del limite in (2.16).
2.5.1 Infiniti e infinitesimi di confronto fondamentali e formule da
ricordare
Se non c’è ragione di fare diversamente, usa confrontare un infinito o un infinitesimo
con
funzioni
particolari, dette gli infiniti o gli infinitesimi di confronto fondamentali. Questi sono
riportati nella tabella 2.6.
Table 2.6: Infiniti e infinitesimi di confronto fondamentali
Alcuni dei limiti elencati al paragrafo 2.1.10 si possono riformulare
come segue: Ciascuno degli infiniti seguenti è di ordine minore
del successivo:
perché
Formule di MacLaurin Vanno ricordate subito le formule della tabella 2.7,
che sono casi particolari della formula di MacLaurin che si studierà più avanti. Le
ultime due righe della tabella si riferiscono a funzioni probabilmente note ad alcuni
studenti, ma non a tutti. Esse verranno introdotte al paragrafo 2.4. Per
interpretare le formule di MacLaurin, vanno conosciuti i simboli seguenti:
- il simbolo
che si legge fattoriale
il numero
deve essere intero non negativo.
Per definizione,
ed . Il
simbolo
per si
definisce per ricorrenza:
e quindi,
- il simbolo ,
che si chiama coeffciente binomiale il numero
deve essere intero non negativo mentre il numero
può essere reale qualsiasi.
Per definizione, |
|
Quindi si definisce
Per esempio, |
|
Si noti che se ,
intero positivo, allora
e quindi
Ciò detto, le formule da ricordare sono nella tavola 2.7.
Table 2.7: Formule di MacLaurin da usare quando
La formula e) si chiama formula del binomio o formula di Newton Nel caso particolare
in cui sia
intero, ,
allora
perché si è visto che .
In questo caso vale di più: si ha |
| (2.17) |
ossia, in questo caso l’errore
è in realtà identicamente zero.
Anche la formula (2.17) si chiama formula di Newton
2.6 Appendice: ancora sulla formula del binomio di Newton
Consideriamo due casi particolari della formula binomiale:
- Si sostituisca
con e si
prenda .
In questo modo
|
|
In questo caso si può trovare un’espressione esplicita per
. Per questo si consideri
il prodotto notevole
|
|
Si ha dunque:
e quindi
- Si noti che se ,
Dunque, se ,
si ha |
| (2.18) |
Vogliamo provare che in realtà ,
ossia che vale la formula del binomio di Newton. Notiamo
che il membro sinistro di (2.18) è un polinomio di grado
:
Notiamo che il coeffciente di
è in ambedue i
membri, ossia che .
Sottraendolo si ha
La funzione
non è cambiata. Dividendo i due membri per
e calcolando il
limite per si vede
che ha lo stesso
coeffciente nei
due membri.
Sottraendo
dai due membri si trova
La funzione
non è cambiata. Ora il procedimento si può ripetere, notando che
ha lo stesso
coeffciente
nei due membri cosìche
e ciò non cambia la funzione .
Ripetiamo il procedimento. Dopo aver sottratto anche
ai due membri si trova
Dunque, la (2.18) in realtà vale con
,
ossia si ha
Ciò giustifica la formula di Newton (2.17). Sostituendo
con
e moltiplicando i
due membri per
si trova
Anche questa formula si chiama formula di Newton
2.7 Alcuni esercizi
- Spiegare perché l’affermazione seguente è falsa: se
non è punto di accumulazione di ,
allora è punto isolato di .
- Usando opportuni esempi, provare che ambedue le affermazioni seguenti
sono sbagliate: 1) la funzione
è continua in
se ;
2) la funzione ,
definita in ,
è continua in
se .
- In ciascuna delle coppie di uguaglianze seguenti, una è corretta e l’altra
sbagliata. Si spieghi il motivo.
Se invece il limite è per ?
- Sia
Mostrare che
- Sia
Si studi ,
per ogni valore del parametro reale
(si ricordi la (1.6)).
- Dire se esiste ,
definita su ,
positiva e con .
Giustificare la risposta.
- Si consideri l’insieme .
Calcolare
ed
e trovare due successioni,
e ,
a valori in
e tali che
- L’insieme
è ancora quello dell’esercizio 7. Si dica se si possono trovare successioni
e
per cui vale
ma che non prendono valori in .
- Sia
l’insieme dell’esercizio 7 e sia .
Dire se esistono successioni
e
a valori in
e tali che
Spiegare come cambia la risposta se invece si chiede che le successioni
abbiano valori in .
- ()
Dire se esiste una funzione positiva, priva di limite per
e illimitata in ogni intorno di .
- Tracciare qualitativamente il grafico della funzione
(
indica la parte intera) e, se esiste, calcolarne il limite per .
- ()
Trovare una funzione pari ed una funzione dispari, limitate e prive di
limite per .
- Mostrare che se
è pari e se
allora si ha anche .
Cosa accade se la funzione è dispari?
- Dire se esiste una funzione periodica dotata di limite per .
- Sia
una funzione periodica tale che .
Dire se
è costante.
- Sia
una funzione dispari che ha un salto per .
Provare che
è discontinuità eliminabile di .
- Si trovi una funzione
definita su
e non costante, tale che
- ()
Si trovi una funzione definita su ,
che ha infiniti punti di discontinuità e tale che
per ogni .
- ()
Dire se esiste una funzione illimitata su
e tale che
per ogni .
- ()
Dire se esiste una funzione definita su ,
illimitata e tale che per ogni
si abbia:
- ()
Siano
e
definite su
e sia .
Si tracci il grafico della funzione
tale che
e il cui grafico negli altri punti è ottenuto congiungendo successivamente
e
mediante segmenti di retta. Quindi:
- supponiamo che
sia un infinito di ordine superiore a .
Mostrare che non è vero che
è un infinito di ordine superiore a .
- ()
Si faccia un esempio per provare che le disuguaglianze
seguenti possono non valere nemmeno se le due funzioni
e
sono strettamente crescenti:
|
| (2.19) |
- ()
si mostri che le disuguaglianze (2.19) valgono se le due funzioni
e
sono convesse;
- si provi che se (finito
o meno) si ha anche
(l’asserto vale sempre, ma si prova più facilmente se le funzioni sono
strettamente convesse);
- si provi che se
allora si ha anche
e quindi
(l’asserto vale sempre, ma si prova più facilmente se le funzioni sono
strettamente convesse).
- ()
Sia
per .
Le due funzioni siano strettamente crescenti ed illimitate e valga, per
,
Sia . Dire se è
vero o meno che ,
,
,
(sempre
per ).
- Sia (per
). Si chiede se
esiste un numero
tale che, per ,
sia .
- Trovare un esempio di funzione
tale che (per
) ma per cui
NON vale né
né
(suggerimento: si provi con le potenze).
- Sia
definita su
e sia
Si scelga come
una delle funzioni ,
,
e si tracci il grafico della corrispondente funzione
.
- Sia
continua su
e sia
Si mostri che è
continua. Può essere che
sia continua anche se
non è continua? Si considerino i due casi
ed
.
- () Per
ogni
si considerino le funzioni definite sull’intervallo
come segue:
fissato ,
si consideri la successione di numeri
. Si provi che
questa converge a
per ogni .
- () Si trovi una funzione
definita su , iniettiva
e tale che e tale che
inoltre non esista .
Table 2.8: Regole di calcolo e forme indeterminate
|
|
| | | | | | Regole | | |
| | | | |
|
| | | | |
| | | |
| | | | |
|
| | | | |
| | | |
| | | | |
|
| | | | |
| | | |
| | | |
|
|
| | | | |
| | | |
| | | |
|
|
| | | | |
| | |
| | | |
|
|
| | | | |
| | | |
| | | |
|
|
| | | | |
| | | |
| | | |
|
|
| | |
Capitolo 3
Velocità, tangenti e derivate
Tutte le leggi sono dettate dall’esperienza, ma
per enunciarle ci vuole un linguaggio speciale;
il linguaggio ordinario è troppo povero e vago
per esprimere dei rapporti cosìdelicati, ricchi
e precisi. Ecco quindi una ragione perchè il
fisico non possa ignorare la matematica. Henri
Poincaré Il valore della scienza
In questo capitolo proseguiamo nello studio delle proprietà locali delle funzioni,
studiandone la proprietà di derivabilità, suggerita dalla meccanica per il calcolo
della velocità istantanea e dell’accelerazione istantanea, e dalla geometria per la
definizione della retta tangente al grafico di una funzione.
3.1 La derivata
Supponiamo che un punto si muova lungo l’asse delle ascisse, e che all’istante
la sua posizione
sia . Abbiamo
cioè una funzione
che rappresenta il moto del punto. fissiamo un intervallo di tempo di estremi
e
(a destra o a
sinistra di ).
Si chiama velocità media del punto su quest’intervallo il numero
Può accadere che esista finito
In fisica, questo numero si chiama “velocità istantanea” del punto all’istante
e si indica col
simbolo oppure con
uno dei simboli
oppure
.
Va detto subito che la velocità media esiste sempre, mentre la velocità
istantanea può esistere o meno. Per esempio non esiste negli istanti nei quali si
verificano degli urti. Se la velocità istantanea esiste per ogni valore di
,
allora si può definire l’“accelerazione media” sull’intervallo di estremi
e
come
Se il limite seguente esiste, questo si chiama l’“accelerazione istantanea” all’istante
:
In ambedue i casi, si incontra quindi un rapporto con al numeratore
l’incremento del valore di una funzione al passare del suo argomento da
, fissato, a
e al denominatore
l’incremento della variabile
indipendente. L’incremento
può essere positivo oppure negativo. Questo rapporto si chiama rapporto incrementale
della funzione che si sta considerando; e del rapporto incrementale si deve fare il limite per
. Un problema
analogo si incontra in geometria, quando si cerca di definire la tangente al grafico di una funzione
definita su
un intervallo .
Sia .
Si vuol definire la tangente al grafico della funzione nel punto
.
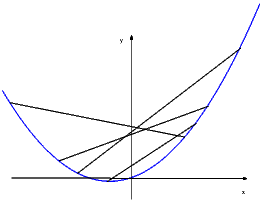
Per questo consideriamo la secante che congiunge i due punti
, considerato
fisso, e il punto ,
variabile sul grafico. Il coeffciente angolare della secante è
e quindi la secante è la retta
Se esiste il limite per
di questi coefficienti angolari,
la retta
si chiama retta tangente al grafico di
nel punto .
Si veda la figura 3.1.
Si vede da qui che il limite del rapporto incrementale compare in applicazioni
diverse, e ce ne sono ancora molte altre. Quindi, questo limite va studiato in
generale.
Definizione 90 Sia
definita su un intervallo
e sia .
Se esiste finito il numero
questo si chiama la derivata della funzione
in
e si indica con uno dei simboli
Un’altra notazione si vedrà più avanti. Il simbolo
è
dovuto a Leibniz e ricorda che la derivata è il limite di un quoziente. NON è
un quoziente e quindi il simbolo non indica una frazione. La notazione
,
di proposito evidenziata in colore, va letta come simbolo unico. Si
osservi che la derivata deve essere un numero. Non può essere
oppure
.
Infatti, molte delle proprietà delle funzioni derivabili che vedremo NON valgono
quando il limite del rapporto incrementale esiste, ma non è finito. Per esempio:
Teorema 91 Se la funzione
è derivabile in
essa è continua in .
Dim. Infatti,
Per ipotesi, il limite del rapporto incrementale esiste finito e quindi
ossia, posto
ed usando il teorema dei limiti delle funzioni composte,
Esempio 92 Il risultato precedente non vale
se il limite del rapporto incrementale è
.
Per vederlo, si consideri la funzione
in .
Essa è discontinua. Il limite del rapporto incrementale esiste, ma non è un
numero:
Un’altro punto a cui fare attenzione è questo: la derivata
si definisce solo nei punti interni al dominio della funzione. Se
oppure
si
possono studiare i due limiti
Se uno dei limiti esiste,
finito o meno, esso si chiama la derivata direzionale in
oppure
in .
La derivata direzionale si può talvolta definire anche in punti
di
non derivabilità. Se esiste, finito o meno, uno dei due limiti
questo si chiama la derivata direzionale,rispettivamente destra oppure sinistra, di
in
. La
derivata direzionale destra o sinistra si indica con uno dei simboli
Sottolineiamo che, a differenza della derivata, la derivata direzionale
non è necessariamente finita.
Una dimostrazione del tutto analoga a quella del Teorema 91 mostra che:
Teorema 93 Se in
esiste finita la derivata destra (o sinistra) di
,
allora la funzione
è continua da destra (rispettivamente, da sinistra) in
.
Concludiamo con una definizione il cui interesse apparirà
principalmente nei corsi successivi. Si chiama differenziale della funzione
in
la
funzione
Questa trasformazione si indica spesso col simbolo
.
Il significato geometrico del differenziale è illustrato al paragrafo 3.2.
Esempio 94 Calcoliamo la derivata di alcune potenze. Se
,
costante, allora
per ogni .
Il rapporto incrementale è nullo e tale è il suo
limite: la derivata di una funzione costante è nulla. Sia
.
Allora,
Sia .
Allora, .
Dunque,
In generale, si ricordi la formula per la somma dei primi
termini di una progressione geometrica:
Si ha quindi |
|
Gli addendi in parentesi sono in numero di
e ciascuno di
essi tende ad
per .
Dunque,
Sia ora
Il rapporto incrementale in
è
e quindi
3.1.1 La funzione derivata e le derivate successive
Ricordiamo che la derivata è un numero che si associa ad un punto
:
.
Può essere però che tale numero esista per ogni
o per
ogni .
In tal caso si costruisce una funzione
che si chiama la funzione derivata di .
Può accadere che la funzione derivata sia ulteriormente derivabile (come
deve essere per definire l’accelerazione). In questo caso, si può calcolare il
numero
che si chiama la derivata seconda di
in . In
questo contesto, la “derivata” si chiama anche derivata prima La derivata seconda
si indica con uno dei simboli
In meccanica, si usa anche il simbolo di Newton
.
Ovviamente:
Teorema 95 Se la funzione
ammette derivata seconda in ogni punto di
allora sia
che
sono continue su .
Quanto detto si può ora ripetere: se la derivata seconda esiste in ogni punto si
può cercare di derivarla, definendo, se esiste, la derivata terza, quarta,
-ma
ecc. Le derivate successive si indicano con i simboli
Ovviamente, le notazioni con gli apostrofi o i punti non sono pratiche
oltre al terzo ordine. In certe formule, conviene indicare la derivata
-ma in
col
simbolo
e in questo contesto si definisce
Sottolineiamo che se esiste la derivata
-ma in ogni
punto di ,
esistono le derivate precedenti, e sono continue in ogni
punto di
. Invece l’esistenza
di nel solo punto
implica l’ esistenza
della derivata
in un intorno di
di
e quindi le derivate precedenti a quella di ordine
sono continue
su mentre la
è continua in
ma potrebbe
essere discontinua in ogni altro punto. Una funzione che ammette le derivate fino all’ordine
incluso su
, continue si
dice di classe
e si scrive
Scrivendo
si intende dire che
è continua su .
Scrivendo
(leggi di
classe
su ) si
intende che la funzione ammette derivate di ogni ordine in ciascun punto di
.
3.2 La prima formula degli incrementi finiti
La sostituzione
mostra che
ossia, essendo
un numero,
Dunque, usando il simbolo di Landau,
Ma,
Dunque,
la derivata ,
se esiste, è quel numero
tale che
Dunque,
verifica
Questa formula si chiama prima formula degli incrementi finiti Viceversa,
se esiste
tale che |
| (3.1) |
allora
Quindi, la prima formula degli incrementi finiti è anche una
equivalente definizione di derivata: la derivata è quel numero
per il
quale è verificata l’uguaglianza (3.1). Ciò ha una conseguenza utile per il calcolo
di certe derivate:
Teorema 96 Sia
definita in un intorno di .
Se per
vale |
| (3.2) |
allora
esiste e
Dim. Infatti, la (3.2) coincide con la prima formula degli incrementi finiti (3.1) scritta con
.
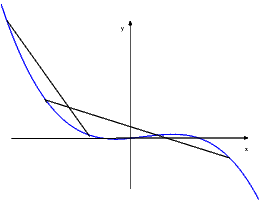
Nella prima formula degli incrementi finiti compare la funzione
che abbiamo chiamato il differenziale della funzione
in
. La prima
formula degli incrementi finiti combinata con l’equazione della retta tangente al grafico
di in
,
ossia
mostra il significato geometrico del differenziale:
è
l’incremento della quota del punto del grafico della funzione, quando si passa
da ad
.
Invece,
Dunque, il differenziale indica l’incremento dell’ordinata del punto della tangente quando
ci si sposta da
ad e
questo incremento differisce dal corrispondente incremento di ordinata sul
grafico della funzione per infinitesimi di ordine superiore al primo rispetto ad
, ossia rispetto
all’incremento
dato all’ascissa. Ciò è illustrato in figura 3.2.
3.3 Regole di calcolo per le derivate prime
Ci sono quattro regole per il calcolo delle derivate: la derivata della somma, del
prodotto, della funzione composta e della funzione inversa. Inoltre, esiste una
formula per la derivata di un quoziente, che si ottiene dalle precedenti.
Derivata di una somma Il limite di una somma è uguale alla
somma dei limiti (quando ambedue esistono finiti). Dunque, se
e
sono
derivabili in
vale
Derivata del prodotto La formula per la derivata del prodotto si chiama
formula di Leibniz e si vede meglio partendo dalla prima formula degli incrementi
finiti. Se
e sono
derivabili in
vale
|
|
Moltiplicando membro a membro si ha |
|
La parentesi graffa è
e quindi
Vale quindi la formula di Leibniz
Supponiamo che
sia costante. Allora,
Dunque,
Combinando quest’osservazione con la regola di derivazione della somma, si
trova:
quando
e
sono numeri
Questa regola si chiama linearità della derivata.
Derivata della funzione composta Siano ora
e
due funzioni e supponiamo che la funzione composta
sia definita su un
intervallo . Sia
e supponiamo
che sia
derivabile in
mentre sia
derivabile in .
Allora vale
I colori sono stati usati per evidenziare il fatto che la derivata della funzione
composta si calcola iniziando col derivare la funzione più esterna. La
dimostrazione è semplice: per ipotesi valgono le due formule degli incrementi finiti
|
|
e inoltre
Si tenga conto di ciò e si sostituisca
con .
Si trova |
|
E’
Dunque, la parentesi graffa è
e la prima formula degli incrementi finiti vale in
per
, con
coeffciente
che è quindi la derivata della funzione composta:
Esempio 97 Ricordiamo che
Consideriamo ora
e una generica funzione
derivabile e non nulla in .
Sia .
La formula di derivazione della funzione composta dà:
Combinando il caso visto nell’Esempio 97 con la formula di derivazione del
prodotto si trova:
Si usi questa formula per provare che
e si calcoli la formula analoga per
e per le corrispondenti funzioni iperboliche.
Esempio 98 Si sa, dalla tabella 2.4, che
(ovviamente se ).
Dunque, se
è derivabile e non nulla,
Applicando questa formula alla funzione
si trova
Ovviamente questa formula vale se ,
perchè in questi punti
non è definita, e se
perché in tali punti si annulla la derivata. Ricordando che
si trovi una funzione la cui derivata è
.
Queste formule sono utili nel calcolo delle
primitive.
Derivata della funzione inversa La regola per il calcolo della derivata della funzione
inversa è più complicata e richiede un’ipotesi in più: si deve avere una funzione
iniettiva e continua
su un intervallo .
Inoltre, la funzione deve essere derivabile in
e deve
essere . Sia
la funzione
inversa di
e sia .
Sotto queste condizioni vale la formula:
Limitiamoci ad illustrare geometricamente questa formula. Ricordiamo che il grafico
di una funzione e della sua funzione inversa devono partire ambedue dall’asse delle
ascisse e che l’uno è il simmetrico dell’altro rispetto alla prima bisettrice.
Le tangenti, quindi, sono simmetriche rispetto alla prima bisettrice. Sia
una retta
passante per .
La sua simmetrica rispetto alla prima bisettrice ha coeffciente angolare
. E
ora ricordiamo che il coeffciente angolare della tangente, quando essa non è
verticale, è la derivata della funzione nel punto che stiamo considerando. Questi
argomenti sono illustrati in figure 3.3.
Vediamo come si usa questa regola per calcolare la derivata della funzione
, funzione inversa
della restrizione a
della funzione .
E’:
Se , la
derivata di
in
è
La tabella 3.1 riassume le regole di derivazione ed elenca le derivate principali che
vanno ricordate. Le regole di calcolo sono state appena dimostrate mentre le
formule delle derivate fondamentali si deducono dai limiti notevoli, combinati con le
regole di calcolo. Notiamo che la tabella non riporta una formula per la derivata di
,
perché invece di ricordare questa formula conviene notare che
La derivata dell’espressione a destra si calcola semplicemente usando la regola di
derivazione delle funzioni composte e quella del prodotto.
Table 3.1: Derivate fondamentali e regole di calcolo
3.4 Notazioni usate nei corsi di fisica
Nei corsi di fisica, e in generale nei corsi a carattere più applicativo, sembra a
prima vista che le notazioni sulle derivate vengano usate in modo alquanto “libero”.
Per esempio, si trova che
In realtà non si tratta di abusi, ma questi procedimenti tengono nascosti
alcuni passaggi che è bene chiarire. Prima di tutto va detto che il simbolo
in
questo contesto viene usato per indicare la derivata, al posto del simbolo
(cosa che noi
faremo al Cap. 4, nel contesto della ricerca delle primitive). Nelle applicazioni, si sottintende
il fatto che la
è a sua volta funzione di una ulteriore variabile, diciamo
, che
non viene indicata. Allora,
che, con la notazione per indicare
la derivata e sottintendendo
la variabile ,
si scrive appunto
Un (apparente) abuso di notazioni analogo si incontra anche
nell’uso del differenziale. Ricordiamo che il differenziale di
in
è la
trasformazione
Questa trasformazione si indica anche col simbolo
:
Nel caso particolare della funzione
la sua trasformazione differenziale è
e ciò suggerisce di scrivere la trasformazione differenziale di
come
(ossia, , ma
usualmente
si sottintende). L’utilità di questa notazione dipende ancora dal fatto che in fisica
è funzione di una
sottintesa variabile
e quindi
è un modo veloce di scrivere il differenziale della funzione composta. Ulteriori apparenti abusi
di notazione,
analoghi ai precedenti, si incontrano quando si devono usare funzioni di
più variabili, e verranno spiegati al paragrafo 8.4 e nel corso di Analisi
Matematica 2.
3.5 Derivate ed ordine dei numeri reali
Sia una funzione
derivabile su .
La relazione di ordine dei numeri reali conduce alla definizione di funzione monotona e,
per mezzo della regola dei segni del prodotto, alla definizione di funzioni pari e
dispari.
Ricordiamo che
è crescente su
quando
Passando al limite per
si trova che e ciò
vale per ogni .
Trattando in modo analogo le funzioni decrescenti si trova:
Teorema 99 Se
è derivabile e crescente (non necessariamente in senso stretto) su
allora
per ogni ;
Se
è derivabile e decrescente (non necessariamente in senso stretto) su
allora
per ogni .
Osservazione 100 E’ opportuno notare gli esempi seguenti:
Il problema della relazione tra derivata e monotonia verrà ripreso
al Cap. 4. Consideriamo ora la relazione tra parità e derivata. Sia
derivabile
si .
Vale: |
|
Derivando i due membri mediante il teorema della funzione composta si trova
|
|
Dunque si ha:
Teorema 101 Sia .
Se
è pari oppure dispari, le sue derivate di ordine pari hanno la stessa parità di
,
quelle di ordine dispari hanno parità opposta.
Una funzione dispari deve annullarsi in
. Vale
quindi:
Teorema 102 La derivata in
di una funzione pari è nulla e quindi se
è pari tutte le sue derivate di ordine dispari sono nulle in
;
se
è dispari tutte le sue derivate di ordine pari sono nulle in
.
E’ interessante vedere l’interpretazione geometrica del Teorema 101 notando
che le secanti in punti corrispondenti del grafico sono parallele, e quindi hanno
la stessa pendenza, nel caso di funzioni dispari; hanno pendenza opposta nel
caso di funzioni pari, come illustrato nella figura 3.5. Tale relazione si conserva
passando al limite dei rapporti incrementali, ossia si conserva per le derivate.
3.5.1 Il teorema di Fermat ed i punti di estremo
Consideriamo una funzione
definita su un intervallo e
sia . punto importante
da sottolineare:
è interno all’intervallo. NON è uno degli estremi. Vale il teorema
seguente:
Teorema 103 (di Fermat) Se:
-
è definita in ;
-
è punto di massimo oppure di minimo locale di
- la funzione
è derivabile in ,
allora .
Dim. Per assurdo, sia
Il teorema di permanenza del segno asserisce che esiste
tale
che
ossia,
Dunque, se
vale
mentre se
vale e
quindi
non è né punto di massimo né punto di minimo di
. Il caso
si tratta in
modo analogo.
L’interpretazione geometrica di questo teorema: ricordiamo che
è la pendenza della tangente al grafico della funzione nel punto
. Dunque, se esiste la
tangente al grafico di
in ed
è
un punto di massimo o di minimo INTERNO AL DOMINIO DELLA
FUNZIONE, la tangente è orizzontale.
Osservazione 104 Il teorema di Fermat NON
si applica alle derivate direzionali. La funzione
,
definita su ,
ha minimo nei punti
e .
Le derivate direzionali in tali punti non sono nulle; anzi sono
e .
La funzione
definita su
ha minimo in
e massimo in .
Le derivate direzionali in ambedue questi punti valgono
.
Il teorema di Fermat ha questa conseguenza importante:
i punti di massimo e di minimo relativo di una funzione vanno cercati
tra i punti nei quali la derivata prima non esiste; i punti nei quali la
derivata prima si annulla e, se ivi definita, gli estremi del dominio della
funzione.
Vediamo alcuni esempi:
Esempio 105 Sia ,
definita su .
La funzione non è derivabile in
e, dove derivabile, ha derivata
Dunque,
non si annulla mai. Quindi, i punti di massimo e di minimo vanno ricercati tra i
punti ,
,
. Sia
invece ,
, definita su
. La derivata si
annulla nel solo punto
e quindi la funzione ha al più un solo punto o di massimo o di minimo, nel punto
. Nel caso
specifico
è punto di minimo ma questo non si deduce dall’annularsi della derivata
prima. Infatti:
- la funzione
ha nulla la derivata nel solo punto
che però ora è un punto di massimo;
- Non è detto che la condizione
implichi che
è punto di massimo o di minimo. Per esempio la funzione
,
definita su ,
ha derivata ,
nulla per .
Il punto
non è né punto di massimo né punto di minimo di
perché
per
mentre
per .
I punti nei quali si annulla la derivata prima si chiamano punti estremali oppure
punti stazionari oppure punti critici della funzione. Il teorema di Fermat asserisce
che i punti di massimo o di minimo (assoluto o relativo) di una funzione sono punti
estremali quando: 1) sono punti interni al dominio; 2) la funzione è derivabile in
tali punti.
3.6 Osservazione finale ed importante
Si è insistito sul fatto che la derivata si definisce nei punti interni. Quindi, quando si afferma
l’esistenza di
implicitamente si afferma anche che la funzione
è definita in un
intorno di ed inoltre, dal
teorema 91, la funzione
è continua in .
Potrebbe essere discontinua in ogni altro punto. Vediamo la conseguenza
di queste osservazioni sulle derivate successive. Affermando che esiste
implicitamente si
afferma che esiste e
quindi anche in un
intorno di . La funzione
deve essere continua
in per il teorema 91.
L’esistenza di in ogni
punto di un intorno di
implica che
è continua in tale intorno. Queste osservazioni si ripetono per le derivate successive: se
esiste allora
è definita in un
intorno di (ed
è continua in );
tutte le derivate precedenti sono definite e continue in tale intorno.
3.7 Alcuni esercizi
-
- Un punto materiale si muove con velocità costante di
.
Calcolarne la velocità in centimetri al secondo.
- Un punto materiale si muove con accelerazione costante di
.
Calcolarne l’accelerazione in centimetri al secondo per secondo.
- la legge del moto del punto suddetto è
quando le lunghezze si misurano in metri e
quando si misurano in centimetri. E’ quindi
.
Ritrovare i risultati precedenti sulla velocità e accelerazione
usando linearità della derivata.
-
- Un punto materiale si muove con velocità costante di
.
Calcolarne la velocità in metri al minuto.
- Un punto materiale si muove con accelerazione costante di
.
Calcolarne l’accelerazione in metri al minuto per minuto.
- la legge del moto del punto suddetto è
quando il tempo si misura in secondi e
quando il tempo si misura in minuti. E’ quindi
.
Ritrovare i risultati precedenti sulla velocità e accelerazione
usando la regola di derivazione della funzione composta.
- Le regole di derivazione mostrano che per ogni numero reale
vale
e simili. Invece,
(si ha qui
ed ).
Dunque, in questo caso il fattore moltiplicativo
“non ha effetto” sul calcolo della derivata. Spiegare il motivo usando le regole
di calcolo dei logaritmi.
- Sia
una funzione derivabile. Dare condizioni per la derivabilità di
in
, sia quando
che quando
. Ha qualche
interesse sapere se
è nullo?
- Si è visto che che se è
pari e derivabile allora
è dispari; se è dispari
e derivabile allora
è pari. Si illustri il significato di questa proprietà tracciando i grafici di due
funzioni, una pari e una dispari, e disegnando alcune tangenti. Ossia, si
considerino le figure 3.7 in alcuni casi concreti.
- () Si mostri che
se è una funzione
derivabile per cui
allora
verifica
se è una funzione
derivabile per cui
allora
verifica
Si verifichi che le funzioni
hanno le proprietà richieste e si verifichi che le loro derivate effettivamente
soddisfano le (3.3) e (3.4).
- ()
Sia
Dire se esitono punti in cui la funzione è continua e punti in cui è
derivabile.
- ()
Sia
Dire se esitono punti in cui la funzione è continua e punti in cui è
derivabile.
- ()
Sia
Dire se esitono punti in cui la funzione è continua e punti in cui è
derivabile.
- () Costruire
una funzione
con queste proprietà:
- è continua in
- per
vale
- la funzione non ha derivata seconda in
.
- ()
Sia
Si mostri che
è di classe
su e che
per si ha
. Dire se è
vero che
(per ).
- Sia
Mostrare che ma che
non esistono intorni di
su cui
è crescente. Si studi la derivabilità della funzione anche per
.
- Sia
Mostrare che ma che
non esistono intorni di
su cui
è crescente. Si studi la derivabilità della funzione anche per
.
- () si costruisca una
funzione di classe
con queste proprietà:
- la funzione è dispari ed
per
(e quindi
per
ed );
- la tangente a grafico nel punto
è orizzontale;
- il punto
non è punto di flesso a tangente orizzontale per la funzione
.
- Si consideri la parabola .
Se ne calcoli la tangente nel punto di coordinate
e si
mostri che tale retta tangente biseca il segmento congiungente il vertice della parabola
col punto .
- Si consideri l’iperbole
e per ogni se ne calcoli
la tangente nel punto .
Si calcoli l’area del triangolo che ha per vertici l’origine e le intersezioni di tale
tangente con gli assi coordinati. Si mostri che l’area del triangolo non dipende da
.
- Sia .
Si considerino i due punti del grafico di
,
ed
.
Si calcolino le tangenti al grafico in tali punti e si calcoli l’ascissa del
loro punto comune. Si noti che tale ascissa è la media aritmetica
dei due
numeri
ed .
- Sia .
Si considerino i due punti del grafico di
,
ed
.
Si calcolino le tangenti al grafico in tali punti e si calcoli l’ascissa del
loro punto comune. Si noti che tale ascissa è la media geometrica
dei due
numeri
ed .
- Elevando al quadrato ambedue i membri membri, si provi che vale la
disuguaglianza
ossia, la media geometrica è minore della media aritmetica. Si usino le
osservazioni agli esercizi 17 e 18. Si traccino i grafici delle due funzioni
ed
e si interpreti la disuguaglianza precedente mediante le ascisse dei punti di
intersezione delle tangenti ai due grafici.
Capitolo 4
Funzioni: proprietà globali
Niente la soddisfa mai, eccetto le dimostrazioni; le teorie non
dimostrate non fanno per lei, non le accetta. E’ questo lo
spirito giusto, lo ammetto: mi attrae, ne sento l’influenza; se
stessi di più con lei, penso che l’adotterei anch’io. Diario di
Adamo, Il diario di Adamo ed Eva di Mark Twain
fino ad ora abbiamo studiato le proprietà “locali” delle funzioni, che
dipendono solamente dal comportamento della funzione in un intorno del punto
. Ora
invece studiamo le proprietà delle funzioni in relazione a tutto il loro dominio, che
frequentemente (ma non sempre) sarà un intervallo.
4.1 Teorema delle funzioni monotone
La definizione di limite permette solamente di verificare che il limite è
effettivamente ciò che l’intuizione ci ha suggerito. In particolare, non asserisce che
un limite debba esistere o meno. Un teorema che asserisce l’esistenza del limite, e ne
indica il valore, è il seguente, che si chiama teorema delle funzioni monotone Lo
enunciamo nel caso delle funzioni crescenti, lasciando per esercizio di adattare
l’asserto al caso delle funzioni decrescenti.
Teorema 106 Sia
una funzione crescente (anche non strettamente). Si ha:
Notiamo che il segno di disuguaglianza è stato
scritto in colore, per sottolineare che le disuguaglianze
sono strette. Anche se la funzione è definita in
,
il valore che essa prende in
non compare nell’enunciato del teorema.
Prima di provare il teorema, vediamone alcune conseguenze.
La dimostrazione del teorema delle funzioni monotone
Proviamo il teorema per i limiti sinistri di funzioni crescenti. Inoltre, studiamo il caso
lasciando per
esercizio il caso in cui .
Conviene distinguere due casi:
Caso 1:
, ossia
superiormente illimitata Come si è notato, in questo caso
è
l’estremo destro del dominio della funzione e bisogna provare
Dunque vanno considerate le disequazioni
e va provato che ciascuna di esse è soddisfatta in un intervallo
, con
.
Essendo la funzione superiormente illimitata, esiste un particolare
tale
che
La funzione è crescente e quindi per
si
ha
Dunque, si può scegliere .
Caso 2:
In questo caso va provato
e quindi vanno considerate le disequazioni
Va mostrato che ciascuna di esse è soddisfatta in un intervallo
.
La definizione di estremo superiore mostra che esiste
per
cui
La funzione è crescente e quindi
L’ultima disuguaglianza discende dalla definizione di
. L’asserto segue scegliendo
.
Ripetiamo che il teorema delle funzioni monotone non richiede che
il dominio sia un intervallo. Esso vale per funzioni definite su un
qualsiasi insieme, purché i limiti da destra e/o da sinistra possano
studiarsi. In particolare, vale per le successioni. Nel caso delle
successioni, il teorema delle funzioni monotone può enunciarsi come segue:
Teorema 107 Se
è una successione monotona, essa ammette limite per
,
finito o meno, e vale:
- se la successione è crescente allora
;
- se la successione è decrescente allora
.
Prendiamo l’occasione offerta dal Teorema 107 per introdurre
un nuovo termine: una successione che ammette limite per
, finito
oppure
oppure ,
si chiama successione regolare Se il limite è finito la successione è una
successione convergente
Si noti che la dimostrazione del Teorema delle funzioni monotone usa
la completezza dei numeri reali, ossia la proprietà di Dedekind.
4.2 Il Teorema di Bolzano-Weierstrass
Ricordiamo che si chiama successione convergente una successione che ammette
limite finito. Il teorema seguente è importante in moltissime applicazioni:
Teorema 108 (di Bolzano-Weierstrass) Ogni successione limitata
ammette sottosuccessioni convergenti, ossia dotate di limite finito.
Dim. Indichiamo con l’estremo
inferiore dell’immagine
della successione,
Ora procediamo in modo iterativo:
-
Passo 1:
- Sia ,
l’immagine della successione e sia
Ovviamente, .
Scegliamo un qualsiasi
tale che
L’indice
esiste per la definizione di estremo superiore.
-
Passo 2:
- Definiamo
Ovviamente,
e quindi .
Scegliamo
tale che
E’:
-
Passo 3:
- Definiamo
Ovviamente,
e quindi .
Scegliamo
tale che
E’:
-
Passo k:
- Definiamo
Ovviamente,
e quindi .
Scegliamo
tale che
e si ha
In questo modo abbiamo costruito due successioni:
- la successione
decrescente ed inferiormente limitata, e quindi dotata di limite finito
:
- la sottosuccessione
della successione .
Si noti che
è effettivamente una sottosuccessione, perché
è crescente, si veda la (4.2).
La (4.1) mostra che ammette
limite, uguale a quello di ,
e quindi finito. Ciò è quanto volevamo provare.
Si noti che la dimostrazione del Teorema di Bolzano-Weierstrass usa
il Teorema delle funzioni monotone e quindi usa la completezza dei
numeri reali .
4.3 Il teorema di Weierstrass
Notiamo che esistono funzioni continue prive di punti di massimo e di minimo. Sono esempi le
funzioni , definita
su , la funzione
definita su
ma anche la
funzione definita
su , che ammette
punto di minimo ()
ma non punto di massimo. In questi esempi le funzioni sono continue su intervalli
che non sono chiusi oppure non sono limitati. Invece:
Teorema 109 (di Weierstrass) Sia
definita su un intervallo
limitato e chiuso .
Supponiamo inoltre che
sia continua su .
L’immagine della funzione ammette sia massimo che minimo e quindi esistono
ed
in
tali
che: |
|
Il teorema non afferma l’unicità dei punti di massimo o di minimo. E’ importante
notare che questo teorema si può riadattare per dimostrare l’esistenza di punti di
massimo e/o di minimo anche in casi in cui le ipotesi non sono soddisfatte.
Consideriamo l’esempio seguente:
Esempio 110
In modo analogo si provi che se
è definita su
e se
allora la funzione ammette punti di minimo
(assoluti).
Supponiamo che la funzione
sia continua su
e verifichi |
| (4.3) |
Esista un punto
tale che .
Allora, la funzione ammette punto di massimo. Infatti, sia
. Per definizione
di limite, esiste
tale che
Dunque, se vale
. Aumentando il
valore di , si può
anche avere . La
funzione è continua
in particolare su ,
intervallo limitato e chiuso, e quindi ammette ivi un punto di massimo
:
In tale punto si ha
più grande di
sia se
che se .
Questo caso è illustrato nei grafici della figura 4.2. Si noti che il grafico a sinistra
mostra anche l’esistenza di un punto di minimo, che però non è conseguenza
della proprietà (4.3). Infatti, la funzione a destra non ha punti di minimo.
In modo analogo si provi che se
è definita su
e se
allora la funzione ammette punti di minimo
(assoluti).
4.3.1 La dimostrazione del Teorema di Weierstrass
Premessa: nella dimostrazione useremo il Teorema di Bolzano Weierstrass e le
proprietà seguenti:
-
A)
- se
è una successione a valori in ,
ossia se ,
e se esiste ,
allora
si ha anche .
-
B)
- se
è continua in
e se
allora
(naturalmente si suppone ).
-
C)
- se una successione converge, ogni sua sottosuccessione converge, ed ha
il medesimo limite, finito o meno (Teorema 83). Applicheremo questo
teorema ad una successione .
Non sapremo che
converge, ma sapremo che .
Se
è una sottosuccessione di
allora
è sottosuccessione di
e quindi .
Proviamo ora il teorema di Weierstrass. Proviamo l’esistenza dei punti di massimo (la
dimostrazione dell’esistenza di punti di minimo è analoga). La dimostrazione è in
tre passi:
Passo 1: la costruzione di una successione massimizzante
Si chiama successione massimizzante per una funzione
definita su un
insieme una
successione
con per
ogni ,
e tale che inoltre
L’estremo superiore può essere finito o meno, e la successione
generalmente non è regolare. Una successione massimizzante
esiste sempre, senza alcuna condizione né sulla funzione
né
sul suo dominio. Infatti, sia
Sia nel caso che
nel caso , esiste
una successione
di punti di che
converge ad . I punti
di sono valori della
funzione e quindi
esiste una successione
tale che .
Dunque,
Passo 2: se
allora esiste una successione massimizzante per
che è anche
convergente.Sia
la successione massimizzante costruita al passo 1. Si ha:
E quindi la successione
è limitata. Per il Teorema di Bolzano-Weierstrass, essa ammette almeno una sottosuccessione
convergente:
Per la proprietà A), il punto
appartiene all’intervallo chiuso .
Inoltre,
è sottosuccessione della successione convergente
e
quindi ha lo
stesso limite :
Paso 3: se è
continua, il punto è
punto di massimo per Sia
il numero costruito al
Passo 2. Si è notato
che
e quindi è un punto del dominio della funzione continua
.
Dunque
si ha:
Ossia, l’immagine della funzione ammette massimo ed
è
punto di massimo. Ciò completa la dimostrazione
Il teorema di Weierstrass dipende dal teorema di Bolzano-Weierstrass
e quindi usa la proprietà di completezza dei numeri reali.
4.4 Teorema dei valori intermedi
Questo teorema afferma che, sotto certe ipotesi, esistono soluzioni dell’equazione
Essenzialmente, le ipotesi sono che 1)
sia continua e 2)
che il grafico di
“tagli quota ”.
Dunque, il contenuto di questi teoremi sembra intuitivo, ma non è per niente
così. Infatti, si consideri l’equazione
Per provare l’esistenza di soluzioni, si può ragionare così: la funzione
vale
per
e vale
per
. Inoltre
è continua. Quindi, il suo grafico “non fa salti” e da qualche parte deve tagliare la
retta ;
ossia l’equazione ammette almeno una soluzione. Questo discorso, dall’apparenza
convincente, è sostanzialmente falso: pensiamo di lavorare con valori di
solamente razionali. Le
condizioni su dette sopra
valgono in , ma nessun
numero razionale verifica .
Dunque, il ragionamento è sbagliato. Proviamo però che l’asserto vale se si lavora in
. Ricordiamo la
differenza essenziale tra
e : in
vale
la proprietà di Dedekind: ogni insieme superiormente limitato ammette
estremo superiore; ogni insieme inferiormente limitato ammette estremo inferiore.
E’ grazie alla proprietà di Dedekind che si può provare il risultato seguente:
Teorema 111 Sia
continua su .
Si consideri l’equazione |
| (4.4) |
Quest’equazione ammette almeno una soluzione se
è compreso
tra ed
.
Il teorema non asserisce l’unicità della soluzione. Prima di provare il teorema,
premettiamo vari commenti. Ricordiamo ora che, Il Teorema di Weierstrass
asserisce l’esistenza di punti di massimo e di minimo della funzione
in
se essa è continua
sull’intervallo .
Esistono cioè
ed in
tali
che
Il Teorema 111 vale anche sull’intervallo di estremi
ed
e
quindi si può enunciare:
Teorema 112 Una funzione continua su un intervallo limitato e chiuso
prende tutti i valori compresi tra il suo minimo e il suo massimo.
L’asserto dei due teoremi 111 e 112 si chiama teorema dei
valori intermedi La versione del teorema che si ottiene quando
e si
sceglie si
chiama teorema di esistenza degli zeri
Teorema 113 (di esistenza degli zeri) Una funzione
continua su
e che ivi prende sia valori positivi che valori negativi, si annulla almeno in un
punto di .
Il teorema dei valori intermedi dipende dalla proprietà di completezza
dei numeri reali, e richiede in modo essenziale che il dominio della
funzione sia un intervallo.
Dimostrato il teorema dei valori intermedi, possiamo anche estendere in vari
modi le considerazioni da cui siamo partiti. Per esempio:
Corollario 114 Se
è continua su
ed inoltre i due limiti (finiti o meno)
hanno segni opposti, la funzione ammette almeno uno zero. In particolare, tutti
i polinomi di grado dispari hanno uno zero in .
Dim. Infatti, il teorema di permanenza del segno garantisce l’esistenza di
tale
che
Si applica quindi il teorema 112 all’intervallo
. Questo risultati
si applica in particolare ai polinomi di grado dispari perché essi sono infiniti di segno opposto
per e per
.
Il Teorema dei valori intermedi mostra che le funzioni continue trasformano
intervalli in intervalli. Più precisamente si ha, usando il Teorema 112:
Corollario 115 Sia
un intervallo (limitato o meno, chiuso o meno). Se
è definita e continua su
allora
è un intervallo. Se inoltre
è un intervallo limitato e chiuso, ,
allora
è un intervallo limitato e chiuso contentente l’intervallo .
Si faccia un esempio per mostrare che in generale
contiene propriamente
l’intervallo .
Interpretiamo ora questi risultati dal punto di vista del grafico di due funzioni:
Corollario 116 Siano
e
due funzioni continue su
e supponiamo che
(o viceversa). I grafici delle due funzioni hanno almeno un punto comune.
Dim. I grafici hanno un punto comune quando esiste una soluzione
dell’equazione
L’esistenza di (almeno) una soluzione di quest’equazione segue dal Teorema 112,
notando che
4.4.1 La dimostrazione del teorema dei valori intermedi
Nella dimostrazione useremo la proprietà seguente, conseguenza del teorema di
permanenza del segno per le funzioni continue: Osservazione: supponiamo che la
funzione sia
continua su
e sia .
Allora si ha:
- se
per
allora
(si noti che si è usato la continuità di
nel punto ).
- sia
una successione per cui ,
ed .
Sempre usando la continuità di
nel punto
si ha .
Proviamo ora il teorema. Per fissare le idee facciamo la dimostrazione nel caso
e quindi
. Naturalmente,
se
oppure
l’asserto è provato e quindi consideriamo il caso in cui le disuguaglianze sono
strette:
Consideriamo l’insieme
L’insieme
è limitato e quindi esiste
Osserviamo che:
- La funzione
è continua e quindi, per (4.5) e per il teorema di permanenza del segno, esiste
tale che
|
| (4.6) |
E quindi
Il punto da sottolineare è che
è interno al dominio della funzione.
- Inoltre si ha:
|
| (4.7) |
La proprietà A) dell’Osservazione mostra che
Proviamo ora che ,
e quindi che
è una soluzione (in generale non l’unica) dell’equazione
.
La dimostrazione consistere nel provare che si ha anche
, cosìche dovrà
essere . Notiamo
che è il massimo
dei minoranti di .
Dunque, per ogni
esiste
tale che
Per il teorema del confornto sui limiti,
. Inoltre,
essendo , si
ha anche .
La proprietà B) dell’Osservazione mostra che
Confrontando (4.8) and (4.9) si conclude che si ha
Ciò prova l’asserto.
4.4.2 Una conseguenza sulle funzioni iniettive
Una funzione strettamente monotona è iniettiva e quindi invertibile. Il contrario
non vale. Si sono visti esempi di funzioni invertibili ma non monotone. Però gli
esempi che abbiamo visto sono
- esempi di funzioni continue ma non definite su un intervallo;
- esempi di funzioni definite su un intervallo ma non continue.
Il teorema seguente mostra la ragione:
Teorema 117 Sia
una funzione continua su un intervallo .
Se essa è iniettiva, allora è strettamente monotona.
Dim. L’iniettività implica che .
Consideriamo il caso
Proviamo che ciò implica che la funzione è strettamente crescente, ossia che per
ogni
ed di
con
si
ha
(l’uguaglianza non può aversi perché la funzione è iniettiva). Consideriamo prima di tutto
i tre punti ,
e
e proviamo
che .
Sia per assurdo
Il teorema dei valori intermedi applicato a
implica
che esiste
tale che .
Ciò non può darsi perché la funzione è iniettiva. Dunque,
e procedendo in modo analogo si vede anche che
Sia ora .
Sull’intervallo
si può lavorare come si è fatto prima sull’intervallo
e si
trova
In definitiva, qualsiasi coppia di punti
,
di
tali che
verifica anche
. E quindi la funzione
è crescente su .
Il caso si tratta in
modo analogo.
4.5 Funzioni derivabili su intervalli
I due teoremi principali che riguardano le funzioni derivabili in tutti i punti di un
intervallo sono il Teorema di Rolle e il Teorema di Lagrange
Teorema 118 (Teorema di Rolle) Sia
una
funzione con le seguenti proprietà:
- il suo dominio è un intervallo
limitato e chiuso;
- è continua nei punti dell’intervallo chiuso ;
- è derivabile nei punti dell’intervallo aperto ;
- vale .
Allora, esiste
tale che .
Dim. Se la funzione è costante, la sua derivata è nulla in ogni punto e quindi un qualsiasi punto
di può scegliersi
come punto . Sia
non costante. La
funzione è continua su ,
limitato e chiuso, e quindi per il Teorema di Weierstrass ammette un punto di minimo
e un punto
di massimo
e vale
perché la funzione non è costante. Dunque non può essere che
ed
siano gli
estremi e
dell’intervallo,
perché in tali punti la funzione prende lo stesso valore. Quindi almeno uno dei due punti
oppure
è interno all’intervallo:
si tratta di un punto
di estremo, interno all’intervallo, e in cui la funzione è
derivabile. In tale punto la derivata è nulla per il Teorema di
Fermat.
Esempio 119 Osserviamo che le ipotesi del Teorema di Rolle non possono essere
eliminate, come provano gli esempi seguenti:
- sia
definita su ,
e sia
se
ed
per
(si faccia il grafico di questa funzione). La funzione è continua sul suo
dominio e derivabile nei punti interni al suo dominio. Inoltre prende lo
stesso valore nell’estremo sinistro e nell’estremo destro del dominio, che
non è un intervallo. La derivata di
non si annulla.
- la funzione
non è continua su
ma verifica le altre ipotesi del Teorema di Rolle. La sua derivata non si
annulla.
- la funzione
non è derivabile su
ma verifica le altre ipotesi del Teorema di Rolle su .
In nessuno dei punti in cui esiste, la derivata prima si annulla.
- la funzione ,
definita su ,
verifica le prime due ipotesi del Teorema di Rolle, ma non la terza. La sua
derivata prima non si annulla.
Se si rimuove l’ultima ipotesi del Teorema di Rolle si trova:
Teorema 120 (Teorema di Lagrange) La funzione
verifichi le seguenti ipotesi:
- è definita su un intervallo limitato e chiuso ;
- è continua nei punti di ;
- è derivabile nei punti di .
Allora, esiste
tale che
Dim. Si noti che
è l’equazione della corda che congiunge i punti del grafico
Dunque, la funzione
verifica le tre ipotesi del Teorema di Rolle. Dunque, esiste
tale
che
Ricordando che
è la pendenza della tangente al grafico della funzione in
si vede il
significato geometrico del Teorema di Lagrange: esiste un punto del grafico in cui la
tangente al grafico stesso è parallela alla corda congiungente i suoi estremi.
Il punto
che figura nel Teorema di Lagrange si chiama punto di Lagrange per
su
.
Il teorema asserisce l’esistenza, sotto le opportune ipotesi, del punto di
Lagrange ma non l’unicità: potrebbero esistere infiniti punti di Lagrange per
sull’intervallo
.
Osservazione 121 Va osservato che:
- il teorema di Rolle implica il Teorema di Lagrange che, a sua volta, si
riduce al Teorema di Rolle se vale .
Ossia, i due teoremi sono equivalenti. Usa tenerli distinti solo per
chiarezza di esposizione;
- come nel caso del Teorema di Rolle, nessuna delle ipotesi del Teorema
di Lagrange si può rimuovere.
- se la funzione è derivabile su ,
allora le ipotesi del Teorema di Lagrange valgono su ogni sottointervallo
di
, e anzi vale di più:
le ipotesi valgono in
se è
derivabile su ,
anche se non è continua negli estremi. Quindi: sia
derivabile
su . Per ogni
coppia di punti ,
di
esiste
tale che
|
| (4.10) |
Il punto
dipende sia da
che da .
- Applicando il teorema di Rolle alla funzione
si può anche provare la seguente generalizzazione del teorema di Lagrange:
Teorema 122 se le due funzioni sono continue su
e derivabili su
e se inoltre
allora esiste
con questa proprietà: le tangenti ai grafici di
e
rispettivamente nei punti
e
(con la medesima ascissa )
sono parallele. Ossia, in tale punto si ha
Si veda la figura 4.3.
La formula (4.10) si chiama seconda formula degli incrementi finiti o anche
formula della media La formula della media si scrive anche |
| (4.11) |
4.5.1 Conseguenze del Teorema di Lagrange
Vediamo due conseguenze importanti del Teorema di Lagrange.
Conseguenza 1) Sia
continua in un intervallo .
Se in ogni punto
dell’intervallo ,
allora è costante
su . Infatti, si
fissi un punto .
Facciamo vedere che in ogni altro punto vale
Per questo, basta notare che la (4.11) implica l’esistenza di
tale
che
L’asserto segue perché .
Di conseguenza:
Lemma 123 Siano
e
definite sul medesimo intervallo
e derivabili in ciascun punto di .
Se per ogni
si ha
allora esiste
tale che
Dim. Infatti, la funzione
ha derivata nulla su
e quindi è costante,
Se
con
costante, si dice che “le due funzioni differiscono per una costante”.
Osservazione 124 L’ipotesi che il dominio delle funzioni sia un intervallo
è essenziale. Per esempio, si considerino le due funzioni
e
definite su
con
e invece .
Ambedue le funzioni hanno derivata nulla in tutti i punti del loro dominio, ma
la loro differenza non è costante. Ciò è conseguenza del fatto che i teoremi
di Rolle e di Lagrange valgono solo quando il dominio della funzione è un
intervallo.
Conseguenza 2) Se
è derivabile su
e se , allora
è crescente
su ; se
è derivabile
su e
se , allora
è decrescente
su .
Sia
su . Si
scelgano ed
arbitrari
in .
La (4.10) mostra che
Il punto
è un opportuno punto, che non è noto; ma comunque
:
Poiché ciò vale per ogni coppia di punti
ed
in
,
segue che la funzione è crescente. In modo analogo si tratta il caso
.
Riassumiamo quanto abbiamo detto nel primo enunciato del teorema seguente:
Dim. La prima affermazione è già stata provata. Proviamo la seconda. La funzione è
crescente in ed
essendo continua in
si ha
La funzione è decrescente in
ed essendo continua in
si ha ancora
In definitiva,
per ogni ,
ossia
è punto di massimo. In modo analogo si tratta il caso del
minimo.
4.6 Le primitive
Siano e
due funzioni definite su
un medesimo intervallo .
La funzione si dice
primitiva di su
se è derivabile
in ogni
e vale
Dunque, una primitiva è sempre una funzione continua. Fatto importante:
mentre la derivata, se esiste, è unica, la primitiva, se esiste, non è mai unica. Infatti,
se , per
ogni
vale:
Dunque,
ed
sono primitive della medesima funzione. Vale anche il viceversa:
Teorema 126 Siano
ed
due primitive della funzione
sul medesimo intervallo .
Esse “differiscono per una costante”, ossia esiste
tale che
Dim. Si veda il Lemma 123.
Di conseguenza:
Corollario 127 Supponiamo che
ammetta primitive su .
Esiste un’unica primitiva
che si annulla in un fissato .
Dim. Sia infatti una
qualsiasi primitiva di
su . La primitiva
che si annulla in
è
L’insieme di tutte le primitive della funzione
su un
intervallo
si indica col simbolo
e si chiama l’integrale indefinito di .
Si noti che:
Noi useremo il simbolo
per intendere quella particolare primitiva che si annulla in
.
VARIABILE MUTA DI INTEGRAZIONE
Il simbolo
indica un insieme di funzioni definite su un (sottinteso) intervallo
.
La lettera che si usa per indicare la variabile indipendente non ha
alcuna influenza sul concetto di primitiva. Per questo potremmo
cambiarla arbitrariamente scrivendo per esempio
ecc. Analogamente, per indicare la primitiva che si annulla in
potremo scrivere
Per questa ragione la lettera che indica la “variabile” sotto il segno di
primitiva si chiama variabile muta d’integrazione
Attenzione che il simbolo
e il termine “integrale”
hanno vari significati concettualmente diversi. Il significato
di “primitiva” è solo uno di essi.
Sebbene questo non sia esplicitamente richiesto dalla
definizione di primitiva, nella maggior parte dei casi le primitive di
su
sono definite e continue
sull’intervallo .
In tal caso,
indicherà quella particolare primitiva che si annulla in
. Se
è una qualsiasi
primitiva (continua in )
di ,
sarà
Infine, notiamo questo teorema, che proveremo in seguito (si veda il Teorema 195):
Teorema 128 Ogni funzione continua su un intervallo ammette ivi
primitive.
Si noti però che esistono funzioni continue la cui primitiva non si può esprimere in
modo elementare. Per esempio, non è possibile rappresentare le primitive di
oppure
di
mediante funzioni “elementari”. Se una funzione definita su
non
è continua, essa può ammettere primitive o meno. E’ importante conoscere il
risultato:
Teorema 129 Se
è definita su
ed ha un salto in
allora essa non ammette primitive.
Per esempio, la funzione
non ammette primitive in nessun intorno di
.
Regole di calcolo per le primitive
NOTAZIONE
In questo paragrafo, useremo lettere maiuscole
e le corrispondenti lettere minuscole,
ed ,
per indicare funzioni. Intenderemo che tra queste coppie di funzioni
valga
Le primitive si calcolano leggendo alla rovescia la tabella delle derivate e usando le
regole di calcolo che ora vediamo e che sono conseguenza della linearità della
derivata, della regola di Leibniz e della regola di derivazione della funzione
composta. Nel calcolo delle primitive, è utile ricordare anche le due formule
seguenti, viste all’esempio 98:
|
| | | |
| |
| | |
|
| | |
Esaminiamo ora come si usano le tre regole di derivazione per il calcolo delle
primitive.
Conseguenza della linearità della derivata è la linearità dell’integrale
ossia
( e
sono
numeri).
Conseguenza della regola di Leibniz è una regola che si chiama integrazione per parti
Siano e
primitive
rispettivamente di
e su
.
Allora vale
Questa regola si ricorda facilemte intendendo che
“” indichi la
derivata, cosìche
indica .
Con questa convenzione, la regola di integrazione per parti si scrive
La regola di integrazione per parti è utile quando è dato da calcolare l’integrale
di sinistra, che non si sa calcolare direttamente, mentre invece si riesce a calcolare
quello di destra.
Esempio 130 Si vogliono le primitive di .
Una primitiva del fattore
è nota (ed è
stessa). Quindi si può procedere cosí:
L’uso “sbagliato” della regola di integrazione per parti conduce in genere ad un
integrale più complicato di quello di partenza, ma questo non sempre è un male.
Esempio 131 La tabella delle derivate non aiuta a calcolare le primitive di
Si conosce però una primitiva di :
Usiamo la formula di integrazione per parti trovando: |
|
Si trova quindi
Conseguenza della regola di derivazione della funzione
composta è la regola di integrazione per sostituzione Sia
una
primitiva di
su e sia
definita
su .
Allora vale
Anche questa regola si ricorda meglio se si integrpreta
“”
come segno di derivata perché cosìessa prende la forma
e si può interpretare come segue: alla
si sostituisce
la “variabile”
e si calcola
Quindi ad si
sostituisce nuovamente .
La semplice formulazione non inganni. Questa è la più diffcile delle regole da
usare e presenta due casi distinti.
-
- Caso 1) L’integrando ha forma
con .
In questo caso, si calcola
e al posto di
si sostituisce .
Esempio 132 Si voglia calcolare
Si scriva quest’integrale come
Si sostituisca
e si noti che
Si sostituisca ora
con .
Si ottiene
-
- Caso 2) La sostituzione “va inventata”.
In questo caso è data da calcolare la primitiva di una funzione
e l’abitudine o la fantasia porta ad immaginare una funzione
tale che sia facile il
calcolo delle primitive di .
Le formule di trigonometria, circolare o iperbolica, spesso suggeriscono la
sostituzione.
Esempio 133 Si vogliono le primitive della funzione
Ovviamente .
Non è affatto evidente come si possano calcolare queste primitive. Però si
nota che
è la metà superiore della circonferenza trigonometrica e, come si è
notato al paragrafo 2.4, ciascun punto della circonferenza trigonometrica si
rappresenta come .
La rappresentazione è unica se si sceglie
e si ha la semicirconferenza superiore se si sceglie .
Ciò suggerisce la trasformazione
Sostituendo
si trova l’integrale
Ricordando la formula di bisezione,
Quindi
Il calcolo però non è concluso. Questa è la primitiva
di
mentre noi
vogliamo . La
funzione su
è invertibile: la sua
funzione inversa è .
Al posto di si
sostituisce ora
e si trova |
|
Usando la formula
si calcolino le primitive di
Primitive di funzioni razionali
Dalla tabella delle derivate si vede che
Combinando quest’osservazione con la linearità dell’integrale, segue che ogni
polinomio ammette primitive, e queste sono polinomi. La tabella delle
derivate mostra che |
|
Dunque, integrando funzioni razionali si possono trovare funzioni “più
complicate”; si possono trovare logaritmi ed arcotangenti. Proviamo ora che
funzioni razionali, logaritmo ed arcotangente bastano ad integrare tutte le funzioni
razionali.
Osservazione sulla notazione
Le primitive devono essere definite su intervalli. Dunque,
ed
non sono funzioni primitive. Sono funzioni primitive le funzioni
|
|
Per non appesantire la notazione, in genere si lascia al lettore di
determinare l’intervallo su cui lavorare. Quest’osservazione, che sembra qui
un po’ capziosa, assumerà un significato fisico importante quando
studieremo le equazioni differenziali.
Ricordiamo che come funzione razionale si intende il quoziente di due
polinomi,
Se il grado di
è maggiore o uguale di quello del denominatore, si può dividere ottenendo
e il grado di è
minore di quello di .
Dato che le primitive dei polinomi si sanno calcolare, basta calcolare le primitive
di
Il calcolo delle primitive ora si fa identificando i poli della funzione razionale; ossia i
punti in cui si annulla il denominatore, che possono essere reali o complessi. I
numeri complessi si studieranno in seguito, ma per i calcoli che ora andiamo a fare
non ne abbiamo realmente bisogno. Il calcolo delle primitive si fa con i metodi
illustrati negli esempi seguenti.
Poli reali semplici E’ il caso in cui
ha grado
ed inoltre
ha
radici distinte. Se ciò vale si dice che la funzione
ha
poli semplici In questo caso si procede come nell’esempio che segue:
Si scrive
come somma:
Riducendo allo stesso denominatore si trova che i tre numeri
,
,
devono verificare
|
| (4.12) |
Quindi, i valori di ,
,
si
trovano risolvendo il sistema
Noti i valori delle costanti ,
e
, il
calcolo della primitiva è immediato. Questo metodo può usarsi tutte le volte che
il denominatore ha tutte le radici reali e distinte.
Risolvere questo sistema è alquanto fastidioso. Un metodo più
semplice è il seguente: sostituendo
nei due membri di (4.12) si trova immediatamente
Analogamente sostituendi
si trova
e sostituendo
si trova il valore di .
Poli reali semplici o meno Se un polinomio
si
fattorizza come
si dice che è uno
zero di molteplicità
di ; e
se è
il denominatore di una funzione razionale il cui numeratore non si annulla in
, si dice
che è un
polo di molteplicità
della funzione razionale. In questo caso si procede come nell’esempio seguente:
Esempio 134
Il polo semplice
si tratta come sopra: gli si fa corrispondere un’addendo
Invece al polo doppio
si fa corrispondere l’addendo
Imponendo
Riducendo allo stesso denominatore si trova che i numeri
,
e
devono verificare l’identità |
| (4.13) |
e quindi
Usando il principio di identità dei polinomi si trova il sistema
da cui
A questo punto si nota che
La primitiva di questi addendi si trova direttamente dalla tavola delle derivate.
Anche in questo caso, può essere più semplice fare opportune
sostituzioni per ricavare immediatamente almeno una parte dei
coefficienti. Per esempio sostituendo
in (4.13) si ottiene immediatamente
e quindi
Sostituendo
si ottiene subito, .
Tenendo conto di ciò e sostituendo
si trova
In generale, ad ogni polo
di molteplicità
si fa corrispondere un addendo |
| (4.14) |
Le primitive di questi addendi possono calcolarsi perché ciascuno di essi a sua
volta può decomporsi come segue: |
| (4.15) |
Talvolta però, specialmente quando
oppure
,
opportuni artifici, come quelli visti all’Esempio 134, conducono al calcolo delle
primitive di (4.14) senza passare attraverso l’ulteriore decomposizione (4.15).
Osservazione 135 Notiamo che |
|
Dunque, il secondo membro di (4.15) si può anche scrivere come
Quindi se per esempio ci sono due poli reali
ed
di
molteplicità
ed (maggiore
di ) a
tali poli si possono associare gli addendi
ossia
ha grado minore di una unità del grado del denominatore. I coefficienti di
si
determinano facendo la derivata del quoziente, riducendo i due membri al medesimo
denominatore e imponendo l’uguaglianza dei polinomi a numeratore. Una volta
determinato ,
la primitive cercate sono
Il caso generale In generale, il denominatore avà anche zeri
non reali. Noi ci limitiamo al caso in cui gli zeri non reali sono
semplici.
Il prototipo è il caso
In questo caso, si può “completare il quadrato”, scrivendo
le cui primitive sono
E ora, nel caso in cui ci siano anche poli reali, semplici o meno, si decompone la
funzione razionale in una somma di termini del tipo
se
è radice reale del denominatore, di molteplicità
. Il polinomio
deve avere
grado .
Le primitive di questi addendi si calcolano come abbiamo già visto. A ciascuno dei
fattori
del denominatore, con discriminante negativo, si fa corrispondere un addendo della
forma
La decomposizione appena descritta delle funzioni razionali si chiama
decomposizione in fratti semplici
Osservazione 136 Il metodo descritto all’Osservazione 135 si può anche
usare quando il denominatore ha fattori ,
privi di zeri. In tal caso si isolano gli addendi
e al denominatore del termine di cui si calcola la derivata si aggiunge un fattore
.
Il grado del polinomio al numeratore (che è da determinare) va aumentato di
.
4.6.1 Primitive generalizzate
Supponiamo che
sia continua su
e che valga
in tutti i punti di ,
salvo un numero finito di essi. In tal caso si dice che
è una
primitiva generalizzata di .
Si noti che
potrebbe non essere derivabile in alcuni punti di
(in
numero finito) e quindi la continuità va imposta esplicitamente. Le primitive
generalizzate si calcolano facilmente procedendo come nell’esempio seguente.
Esempio 137 Sia
Le funzioni
verificano rispettivamente
La funzione
per
ed
per
NON è una primitiva di
perché non è definita in ;
e non lo è in generale nemmeno se si assegna ad essa un valore in
perché in generale non sarà continua. Però vale
Si imponga allora prima di tutto l’uguaglianza dei limiti ossia in
quest’esempio si imponga
Quindi si estenda
per continuità anche nel punto
ossia, in quest’esempio si imponga
Si è trovata cosìuna primitiva generalizzata di .
Dunque, l’insieme di tutte le primitive generalizzate di
è
Si noti che la
non era definita in ,
mentre
deve essere definita su un intervallo, e quindi anche in .
Se si fosse assegnato
o qualsiasi altro numero, niente sarebbe cambiato nella procedura descritta.
Infatti, non si richiede né che
sia derivabile in
né, se derivabile, si richiede .
Dunque, le funzioni
sono anche le primitive di
L’esempio precedente si adatta in generale e in particolare si potrebbe provare che
l’insieme delle primitive generalizzate, se non è vuoto, dipende da una
(sola) costante arbitraria.
4.7 Alcuni esercizi
- ()
Il teorema dei valori intermedi asserisce che una funzione continua
trasforma intervalli in intervalli. Si mostri che esistono funzioni non
continue che hanno questa proprietà esaminando le funzioni
Si consideri separatamente il caso
ed il caso
e si noti che, in uno dei due casi, questa funzione, discontinua in
,
trasforma intervalli in intervalli.
- Il teorema dei valori intermedi combinato col teorema di Weierstrass
implica che una funzione continua definita su un intervallo chiuso lo
trasforma in un intervallo chiuso. L’asserto analogo non vale per gli
intervalli aperti: si costruisca un esempio di funzione continua su un
intervallo aperto, la cui immagine è un intervallo chiuso.
- ()
Le funzioni monotone che trasformano intervalli in intervalli sono
ovunque continue. Si spieghi la ragione e si mostri un esempio di funzione
monotona definita su ,
con un unico punto di discontinuità e la cui immagine non contiene
l’insieme
ma contiene il punto .
- Sia
monotona su .
Mostrare che la funzione ha sia punti di massimo che di minimo assoluto.
- ()
Sia
crescente su
e sia
un suo punto di discontinuità. Si vuol sapere se è possibile che
ambedue gli insiemi
ed
siano intervalli chiusi.
- Sia
crescente su
e sia
un suo punto di discontinuità. Si vuol sapere se è possibile che l’insieme
sia un intervallo aperto.
- ()
Sia
monotona su
e sia .
Supponiamo che esista .
Mostrare che
è continua in .
Vale quest’asserto se
oppure ?
- per
sia
(si ricordi che
indica la mantissa di ).
Tracciare il grafico di ,
studiarne la monotonia e la continuità su .
- Sia
e sia .
Provare che se i grafici delle due funzioni si intersecano in due punti allora
la tangente al grafico di
ha pendenza
in almeno un punto. Provare inoltre che esiste un intervallo
su cui
è crescente.
- ()
Usando il teorema di Rolle, si provi che se una funzione è di classe
su
e se
non si annulla allora ogni coppia di tangenti al grafico di
si interseca.
- ()
Su
vale .
Usare questa proprietà, il teorema di Rolle ed il teorema dei valori
intermedi per provare che
sia per
che per .
- Si è visto che
Spiegare se è vero o meno che le due funzioni
e
differiscono per una costante.
- Le due funzioni
e
sono definite sul medesimo intervallo
e su
hanno la stessa derivata. Dunque differiscono per una costante. Trovare
il valore della costante e illustrare questo fatto geometricamente a partire
dai grafici delle funzioni
e
(si confronti con l’esercizio 39 del Capitolo 1).
- Sia
Mostrare che .
Tracciare il grafico delle funzioni e notare che le due funzioni non
differiscono per una costante. Spiegare.
- Sia
Notare che
E’ vero che
è costante?
- Si mostri, sia mediante le formule di trigonometria che mediante il calcolo
delle derivate:
- Mostrare che
è costante per
e per
e calcolarne i valori.
- ()
Si ricordi che
Dire se si può applicare questa formula con
per calcolare il valore di .
Usare il risultato trovato all’esercizio 17.
- Rolle (1652-1719) enuncia il suo teorema nel suo libro Traité d’algebre
del 1690, limitandosi a considerare “funzioni algebriche”, ossia funzioni
espresse mediante polinomi. Con linguaggio moderno, l’enunciato di
Rolle è il seguente: tra due zeri reali consecutivi della derivata di una
funzione algebrica si trova al più uno zero della funzione stessa. Si
provi che questo enunciato è vero usando la formulazione moderna del
Teorema di Rolle, ossia l’enunciato del Teorema 118.
- Si calcolino le primitive
e si mostri che l’uguaglianza
non è corretta. Si trovi l’espressione giusta. In modo analogo si tratti
- Siano
e
due funzioni dotate di primitive
e
su un intervallo .
Sia
e sia
per .
Si deduca che vale la proprietà di monotonia del calcolo delle primitive
per .
- Sia
e sia
su .
Usando il Teorema di Lagrange, si mostri che per ogni coppia di punti
ed
in
vale
- ()
Sia
primitiva su
della funzione
continua su
e valga .
Siano
ed
funzioni continue su un intervallo ,
a valori in .
Mostrare che
Capitolo 5
Teoremi di l’Hospital e di Taylor
Ormai so che l’acqua scorre sempre verso il basso, se non
quando è buio. So che questo accade perché lo stagno non
si prosciuga mai, come naturalmente succederebbe se l’acqua
non ritornasse in su. Diario di Eva, Il diario di Adamo ed Eva
di Mark Twain
In questo capitolo si presentano i Teoremi di l’Hospital e la formula di Taylor e le loro
conseguenze, concludendo lo studio sia locale che globale delle funzioni. Il Teorema
di L’Hospital serve per il calcolo dei limiti quando si incontrano forme
indeterminate di tipo fratto mentre la formula di Taylor estende la prima
e la seconda formula degli incrementi finiti al caso in cui una funzione
ammette più derivate.
5.1 Teorema di l’Hospital
E’ un teorema che è utile per il calcolo di limiti nel caso che si incontri una forma
indeterminata di tipo fratto,
nel calcolo di un limite per
dove può essere
un numero oppure
oppure .
Anzi, se
il Teorema di l’Hospital si può usare anche per il calcolo dei limiti direzionali
oppure
. Illustriamolo nel
caso del limite per
intendendo che se questo
sarà il limite per .
Ricordiamo lo scopo: calcolare
quando si incontra la forma indeterminata
oppure
. Le
ipotesi sono le seguenti:
Il teorema asserisce:
Teorema 138 (di l’Hospital) Se valgono le ipotesi enunciate sopra, esiste
e inoltre, con
dato da (5.1),
La dimostrazione, alquanto complessa, viene omessa.
Esempio 139 Illustriamo alcuni esempi ed alcuni problemi che possono
incontrarsi nell’uso di questo teorema.
- Consideriamo il limite
Le funzioni a numeratore e denominatore verificano le ipotesi del
Teorema di l’Hospital e inoltre (
indica l’operazione di derivazione)
Quindi si ha anche
In modo analogo si provi che
- Consideriamo ora
Proviamo a fare il quoziente delle derivate. Si trova
Dato che, grazie ad un preventivo uso del teorema di l’Hospital, questo
limite si conosce, ed è ,
e le altre ipotesi del teorema valgono, si può concludere che
Ossia, il teorema di l’Hospital si può applicare più volte in sequenza.
- Non è detto che il Teorema di L’Hospital permetta sempre di calcolare
il limite, nemmeno se le ipotesi sono soddisfatte. Per esempio, sia
e .
E’ immediato dalla definizione delle funzioni iperboliche che
Tutte le ipotesi del teorema di l’Hospital valgono per questo quoziente,
ma il teorema stesso non serve al calcolo del limite perché derivando
numeratore e denominatore si trova alternativamente
Ossia, usando quante volte si voglia il teorema di l’Hospital si finisce
sempre sulla medesima forma indeterminata. Un esempio simile è il
calcolo del limite
Il quoziente delle derivate è
e quindi fa intervenire nuovamente proprio il quoziente di cui si intendeva
calcolare il limite. Si noti che questo limite è stato calcolato per
sostituzione all’Esempio 84.
- Può anche essere che il limite del quoziente delle funzioni esista, ma
che non esista quello del quoziente delle derivate. Notando che
si vede che
Se si calcola il quoziente delle derivate si trova
privo di limite per ,
nonostante che le altre condizioni del teorema di l’Hospital siano
soddisfatte.
- Se si usa il teorema di L’Hospital quando le ipotesi non sono soddisfatte,
si possono trovare risultati sbagliati. Per esempio,
Le ipotesi del teorema di L’Hospital non sono soddisfatte da questo
quoziente, che non conduce ad una forma indeterminata. Facendo il
limite del quoziente delle derivate si trova
- Il teorema di L’Hospital talvolta può applicarsi e conduce al risultato
corretto, ma il calcolo fatto è fallace perché tautologico; ossia perché
usa proprio l’informazione che si sta cercando. Per esempio, usando il
teorema di L’Hospital,
Sembra quindi di aver trovato un modo molto veloce per il calcolo del
limite notevole. Ciò è però falso perché in questo calcolo si è usato
,
formula che si dimostra proprio a partire dal limite notevole di
.
- Infine, notiamo che col teorema di l’Hospital si possono anche calcolare
certi limiti che apparentemente non sono nella forma di quoziente. Per
esempio, si voglia studiare
Scrivendo questo limite come
si ha una forma indeterminata
a cui il Teorema di l’Hospital può applicarsi. Il quoziente delle derivate
è
e quindi
Di consequenza si deduce anche
Infine, osserviamo la seguente conseguenza del Teorema di l’Hospital. Sia
una
primitiva di
sull’intervallo
e supponiamo che
Usiamo il Teorema di l’Hospital per calcolare |
|
Ciò mostra che
Più in generale,
Teorema 140 Sia
primitiva di
sull’intervallo
e supponiamo che
Allora,
5.1.1 Calcolo di derivate direzionali
Un argomento analogo a quello usato nella dimostrazione del Teorema 140 dà
anche un modo molto utile che può usarsi per il calcolo di derivate direzionali. Il
problema è questo: talvolta si può provare che una funzione è derivabile su
e su
e usando le regole di derivazione se ne calcola facilmente la derivata.
E’ invece diffcile vedere se esistono le derivate direzionali in
. Una condizione suffciente
per l’esistenza di
è la seguente:
Teorema 141 Sia
continua in
e inoltre derivabile in .
Se esiste il limite direzionale ,
ossia se siste
allora esiste anche la derivata direzionale
e inoltre si ha l’uguaglianza
Dim. Per definizione,
Il limite è una forma indeterminata
, perché la funzione
è continua in .
Per il calcolo di questo limite si può usare il teorema di l’Hospital,
ovviamente se l’ultimo limite scritto
esiste.
Asserto analogo vale per la derivata sinistra:
Teorema 142 Sia
continua in
e inoltre derivabile in .
Se esiste
allora esiste
e inoltre
E quindi:
Teorema 143 Se
è
- derivabile in
- derivabile in
- continua in
- esiste
allora la funzione
è derivabile in
e vale
Osservazione 144 L’ipotesi che
sia continua in
è essenziale nel Teorema 143. Se non vale, le tangenti nei punti
tendono a diventare parallele quando ,
senza sovrapporsi per ,
si veda la figura 5.1.
Segue dal Teorema 143:
Corollario 145 Se
è definita su
e discontinua in
allora la discontinuità è di seconda specie.
Dim. Ricordiamo che
ha discontinuità eliminabile oppure di prima specie in
quando esistono ambedue
i limiti direzionali
e , ed uno almeno
è diverso da .
Per ipotesi,
esiste e quindi
è continua in .
Il teorema precedente garantisce che i due limiti direzionali, se esistono, valgono
; ossia
non può essere né punto di salto né discontinuità eliminabile di
.
Questo risultato permette in particolare di asserire che la funzione
non è una funzione derivata in nessun intorno di
, e
quindi non ammette primitive. Esistono però funzioni ovunque derivabili, la
cui derivata ammette discontinuità di seconda specie. Un esempio è la funzione
per
, ed
.
5.2 La formula di Taylor
La formula di Taylor è un’estensione della prima o della seconda formula degli
incrementi finiti. Vediamo separatamente i due casi.
5.2.1 La formula di Taylor con resto in forma di Peano
La formula di Taylor (con resto in forma di Peano) è un’estensione
della prima formula degli incrementi finiti a funzioni che in un punto
hanno più di una derivata. Notiamo che:
- il punto
è indicato in colore, ,
per sottolineare che è considerato fissato, mentre la variabile si indica
con ;
- se una funzione ha
derivate in
allora ha
derivate in un intorno di .
Supponiamo che in
esista la derivata seconda. Allora, si può scrivere la prima formula degli incrementi finiti
in per la
funzione : |
| (5.2) |
Per definizione, ammette
primitive e ammette
primitive. Dunque anche
ammette primitive. Le primitive che si annullano in
di
, di
e di
(funzioni
della variabile )
sono rispettivamente |
|
Come si è notato, da (5.2) si vede che anche
ammette primitive e, per il Teorema 140,
Uguagliando le primitive che si annullano in
dei
due membri di (5.2) si trova
Quest’argomento si può ripetere se ci sono derivate di ordine successivo. Per esempio, se c’è la
derivata terza in ,
si può scrivere la prima formula degli incrementi finiti per
,
Prendendo due volte le primitive dei due membri che si annullano in
si
trova
In generale, se
ammette
derivate in ,
si trova
Questa formula si chiama formula di Taylor con resto in forma di Peano e, più
precisamente:
- il punto
si chiama il centro della formula di Taylor;
- il polinomio, della variabile ,
si chiama il polinomio di Taylor di ordine
di ,
di centro ;
-
si chiama il resto in forma di Peano
- E’ particolarmente importante il caso in cui :
Questa formula si chiama formula di MacLaurin Ovviamente, essa è
solamente un caso particolare della formula di Taylor. Per esercizio, si
mostri che le formule degli infinitesimi fondamentali nella tavola 2.7 sono
particolari formule di MacLaurin.
Osservazione 146 Sia
una funzione dotata di derivata -mma
in
e sia
il suo polinomio di Taylor di grado
e centro .
Esso verifica
Si potrebbe provare che nessun altro polinomio di grado
in
ha questa proprietà.
5.2.2 La formula di Taylor con resto in forma di Lagrange
La formula di Taylor (con resto in forma di Lagrange) è un’estensione della seconda formula
degli incrementi finiti a funzioni che hanno più di una derivata in un intorno di
. Limitiamoci ad
enunciarla. Sia
definita su ed
ivi dotata di
derivate. Sia .
Supponiamo che
esista in .
Allora esiste
tale che
Analogo risultato vale, con
se esiste
in .
L’errore
si chiama resto in forma di Lagrange
5.2.3 Polinomio di McLaurin e parità di una funzione
Ricordiamo che una funzione
dispari e definita in
è ivi nulla. Quest’osservazione è stata usata al paragrafo 3.5 per provare
che le derivate di ordine dispari di una funzione pari sono nulle in
;
le derivate di ordine pari di una funzione dispari sono nulle in
(si
veda il Teorema 102). Possiamo quindi enunciare:
Teorema 147 Sia polinomio
di McLaurin di una funzione .
Allora:
- se la funzione è pari, le potenze
con
dispari hanno coeffciente nullo;
- se la funzione è dispari, le potenze
con
pari hanno coeffciente nullo.
Naturalmente, non è vietato che anche i coefficienti di alcune potenze pari siano nulli quando
è pari (ed analoga
osservazione quando
è dispari).
5.3 Estremi e convessità
Al Teorema 125 abbiamo visto che i punti di massimo o di minimo di una funzione
continua su un intervallo possono individuarsi studiando la monotonia della
funzione a destra e a sinistra del punto. Qui mostriamo che si possono anche
studiare esaminando le derivate successive nel punto stesso. Inoltre, mostreremo
come studiare la convessità di una funzione.
5.3.1 Derivate successive ed estremi
Sia derivabile
due volte in .
Se allora
certamente non
è né punto di massimo né punto di minimo (si ricordi il Teorema di Fermat). Supponiamo
quindi .
Si ha:
Teorema 148 Se
e
allora il punto
è punto di minimo; Se
e
il punto
è punto di massimo per .
Dim. Scriviamo la formula di Taylor di centro
arrestata al secondo ordine, con resto in forma di Peano. Ricordando che
si
vede che
Per , la
funzione tende
ad e quindi in
un intorno di
ha il segno di ;
il fattore
è maggiore o uguale a zero e quindi in tale intorno
Niente può dirsi se .
Però, una dimostrazione in tutto analoga prova che:
Teorema 149 Esista
e sia
per ogni .
Se
il punto
è punto di minimo; se
il punto
è punto di massimo per .
5.3.2 Convessità e punti di flesso
Ricordiamo la definizione di convessità data al paragrafo 1.8.3: una funzione è convessa su un
intervallo quando per
ogni coppia di punti
ed di
, la corda
che unisce
ed
sta sopra al grafico della restrizione della funzione ad
.
Ricordiamo anche che una funzione è concava quando
è convessa.
La definizione di convessità è stata data usando le secanti, che esistono anche se
non è derivabile.
Se però è
derivabile su
allora si ha il risultato seguente, illustrato nella figura 5.2 e che non proviamo:
Teorema 150 La funzione
è convessa su
se e solo se per ogni
e per ogni
si ha
Ossia, la funzione derivabile
è convessa su
se e solo se il suo grafico è ovunque sopra a ciascuna delle tangenti
nei punti del grafico stesso. Si enunci la proprietà analoga per le funzioni
derivabili e concave.
Questa proprietà di tipo geometrico si formula in modo
analitico usando la formula di Taylor. Supponiamo che esista
e scriviamo la formula
di Taylor di centro
e resto in forma di Lagrange: |
| (5.3) |
Quest’uguaglianza mostra che
se per
ogni
allora
Dunque:
Teorema 151 Sia
due volte derivabile su .
La funzione
è convessa su
se e solo se
per ogni .
Sia ora una funzione
di classe . Se
allora, per il teorema di
permanenza del segno,
in un intorno di
e in tale intorno la funzione è convessa. Se invece
ed
cresce oppure decresce, allora la funzione è convessa da una parte di
e
concava dall’altra. Un caso in cui ciò avviene è il seguente:
Teorema 152 Sia
di classe
e sia
ed .
In questo caso la funzione è convessa da una parte di
e concava dall’altra.
Dim. Sia per esempio .
Allora, per il teorema di permanenza del segno applicato alla funzione
, che è continua,
rimane positiva in
un intorno di . In tale
intorno, è crescente
e quindi negativa per
(dove la funzione è concava) e positiva per
(dove la funzione è convessa. Si tratti in modo analogo il caso
.
Consideriamo più in dettaglio il caso di
di classe
, con
ma
. Per fissare
le idee sia
cosìche
per
ed
per :
la funzione è concava a sinistra e convessa a destra di
. Dunque, a
sinistra di
il grafico è sotto le tangenti ed a destra è sopra. Vediamo cosa accade in
.
Scrivendo la formula di Taylor con resto in forma di Peano si vede che
Se ,
l’uguaglianza precedente mostra che il grafico della funzione taglia la tangente al
grafico in
e in particolare il grafico è sotto alla tangente per
e sopra
per .
Ciò suggerisce la definizione seguente:
Definizione 153 Sia
una funzione derivabile su un intervallo
che contiene .
Se la funzione è convessa su
e concava su
(o viceversa), il punto
si dice punto di flesso per .
Si dice che
è punto di flesso ascendente per
se il grafico di
è sotto la tangente in
per
e sopra per ;
Il punto
si dice punto di flesso discendente se il grafico di
è sopra la tangente in
per
e sotto per .
Se
è punto di flesso ed inoltre ,
allora si dice che
è punto di flesso a tangente orizzontale
Riassumendo
Teorema 154 Sia
e sia .
Se
mentre
allora
è punto di flesso. Il flesso è ascendente se ,
discendente se .
Naturalmente, può accadere che anche
sia nulla. Cosìcome fatto per gli estremi, si possono guardare (se esistono) le
derivate successive e si ha:
Teorema 155 Se la prima derivata non nulla di
in
di ordine maggiore di
è di ordine dispari, la funzione ha punto di flesso in .
Il flesso è ascendente se tale derivata è positiva, discendente altrimenti.
5.4 Alcuni esercizi
- Sia ,
con
primitiva di .
Si è visto (al Teorema 140) che
per
implica che .
Si vuol sapere se ciò vale solamente per
intero, o se vale per qualsiasi esponente positivo (ovviamente restringendosi
alle ).
- ()
Ancora con riferimento al Teorema 140: supponiamo di sapere che
per .
Mostrare su un esempio che in generale non vale
per
(un esempio si trova all’esercizio 11 del Cap. 3).
- Per
sia .
Siano
e
primitive rispettivamente di
e di .
Supponiamo che .
Si chiede se vale .
- Trovare esempi di funzioni diverse
e
, di classe
, i cui grafici
hanno un punto
comune e tali che valga una delle ulteriori proprietà seguenti:
-
è punto di massimo oppure di minimo per ambedue le funzioni;
-
sia punto di massimo per l’una e di minimo per l’altra;
- una delle due sia convessa e l’altra concava.
() Può
essere che
sia asintoto verticale per una delle due funzioni?
- Sia
derivabile su
e illimitata. Si mostri che se esiste un asintoto obliquo
allora
.
- ()
Sia
asintoto obliquo destro della funzione derivabile
. E’ vero che
deve esistere ?
- () Si consideri la
funzione cosídefinita: ;
.
Negli altri punti il grafico si ottiene congiungendo con segmenti i punti
ed
. Si
tracci il grafico della funzione. Questa funzione è derivabile salvo che nei punti
ed
. Si dica
se esiste .
Si illustri qualitativamente come sia possibile modificare il grafico di questa
funzione, in modo da rispondere alla domanda 6.
- Si mostri un esempio di funzione monotona la cui derivata prima ammette zeri. E’ possibile
che ammetta
infiniti zeri su ?
E su un intervallo limitato?
- Si sa che è
continua in
e che per
vale
Si noti che questa funzione è derivabile per
(Teorema 96) ma che l’espressione scritta può non essere una formula di Taylor, perché la
potrebbe non essere
derivabile per . Ciò
nonostante, si provi che
è punto di minimo locale della funzione.
- () Sapendo
solamente che
è continua in
e che per
vale
può dedursi che è
punto di flesso di ?
Anche se ?
- Le due funzioni
e siano
di calsse
e per
valga
Cosa può dedursi sulle tangenti alle due funzioni? E se invece
cosa può dedursi sulle tangenti?
- Trovare una coppia di funzioni derivabili su
,
tali che
ma tali che nessuna retta sia tangente ad ambedue le funzioni.
- ()
Talvolta si trova la seguente come definizione di flesso: la funzione derivabile
ha flesso
in
se il grafico traversa la tangente nel punto
.
Dire se questa definizione e quella data al paragrafo 5.3.2 si equivalgono.
Si consideri la funzione all’esercizio 47 del Capitolo 1. Si dica se
è punto di flesso per questa funzione, per la definizione appena data, per la
definizione al paragrafo 5.3.2, o per ambedue.
- Sia una funzione
di classe
con .
Mostrare che le due definizioni di punto di flesso, quella del paragrafo 5.3.2 e
quella dell’esercizio 13, coincidono.
- Sia se
, ed
altrimenti. Mostrare
che il punto
è punto critico, ossia che la funzione è derivabile in
,
con derivata uguale a zero, ma che il punto
non è né punto di massimo, né punto di minimo, né punto di
flesso.
- Calcolare
Verificare se questa funzione verifica o meno le condizioni del teorema di
l’Hospital e studiare il limite del quoziente delle derivate.
Capitolo 6
Ricapitolazioni
Il Trònfero s’ammalvola in
verbizie
incanticando sbèrboli giocaci
sbramìna con solènnidi e
vulpizie
tra i tavoli e gli ortèdoni fugaci.
Fosco Maraini, Via Veneto, in Gnòsi delle
Fànfole.
In questo capitolo ricapitoliamo alcuni dei concetti fondamentali incontrati fino ad ora.
Ossia, ricapitoliamo i concetti relativi alle successioni, incontrati in particolare nei
capitoli 1 e 2. La ricapitolazione relativa alle funzioni si otterrà mostrando come i
concetti studiati si possano usare per tracciare qualitativamente i grafici di funzioni.
Naturalmente, definizioni e teoremi vanno studiati ciascuno nel proprio
capitolo.
6.1 le successioni
Ricordiamo che
indica l’insieme dei numeri naturali (incluso o meno
, come
generalmente si deduce dal contesto) e che una successione è una funzione il cui dominio
è .
Il simbolo usato per indicare una successione, invece di
, è
oppure
. Quando,
come spesso accade, si intende che la successione prenda valori sull’asse delle ascisse,
scriveremo
oppure .
Il simbolo
è ambiguo perché indica sia la successione, ossia la funzione
,
che l’insieme dei numeri ,
ossia l’immagine della successione. Il significato va capito dal contesto.
Il grafico di una successione è l’insieme delle coppie
,
che si rappresenta sul piano cartesiano come nell’esempio della
figura 6.1, a sinistra. Si noti che in questa figura abbiamo indicato con
l’asse delle
ascisse e con
quello delle ordinate, per coerenza con il simbolo
usato per
la successione. Quest’esempio aiuta anche a capire la differenza tra i due significati del
simbolo .
La figura 6.1, a sinistra riporta il grafico della funzione
mentre a destra ne riporta l’immagine, ossia l’insieme
.
figure 6.1: Successione e immagine: II grafico della successione
è l'insieme dei punti del piano cartesiano
L'immagine della successione è l'insieme dei punti sulla retta
Grafico della successione
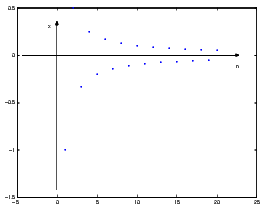 La sua immagine
La sua immagine 
In pratica però tracciare il grafico di una successione non è molto utile perché
di una successione interessa il “comportamento asintotico”, ossia il comportamento
per e
questo non si vede disegnando pochi punti del grafico. Una successione è crescente
se
implica
(se
implica
la successione si dice strettamente crescente). Si diano le definizioni di successione
decrescente e strettamente decrescente. Una successione strettamente monotona
(crescente o decrescente) è una trasformazione iniettiva e quindi invertibile.
Gli unici limiti che possono studiarsi per una successione sono i limiti per
. In
particolare una successione si dice
- regolare se
esiste, uguale a ,
a
oppure ad .
- altrimenti, la successione si dice indeterminata o oscillante
Le definizioni di limite di una successione sono state studiate al paragrafo 2. Dato che
l’unico caso di limite che può studiarsi per una successione è quello per
, invece di scrivere
, si può scrivere
piuù brevemente .
Infine, ricordiamo che per le successioni vale il teorema delle funzioni monotone, che
può enunciarsi come segue:
Teorema 156 Ogni successione monotona è regolare e precisamente vale:
- se la successione
è crescente,
- se la successione
è decrescente,
Per interpretare l’enunciato di questo teorema, è importante aver capito i due significati diversi
della notazione .
Infine, ricordiamo il limite notevole
Combinando questo limite col teorema sui limiti di funzioni composte, si trova:
|
|
6.2 Studi di funzione
Si chiama “studio di funzione” il processo che conduce a tracciare qualitativamente
il grafico di una funzione, individuandone dei punti particolarmente significativi.
Nel fare ciò, si devono usare tutte le nozioni che abbiamo incontrato fino ad ora e
conviene procedere con un certo metodo. Elenchiamone i punti salienti e poi
commentiamoli.
-
- A) il primo passo consiste nel determinare il dominio della funzione.
-
- B) si determinano eventuali simmetrie e periodicità
-
- C) Determinazione dei limiti (per
tendente agli estremi del dominio o ad altri punti notevoli) e degli
eventuali asintoti.
-
- D) Si studia quindi la continuità della funzione, identificando gli eventuali
punti di discontinuità.
-
- E) Si studia la derivabilità della funzione, individuando gli eventuali punti
di non derivabilità.
-
- F) Si determinano gli intervalli di monotonia ed i punti di estremo della
funzione.
-
- G) Si studia la convessità della funzione.
NOTA IMPORTANTE In
un compito d’esame usualmente viene proposta una funzione e vengono
richieste solamente alcune delle proprietà del grafico. Per esempio, lo
studio della convessità potrebbe non essere richiesto. Ciò non solo
perché è diffcile, ma anche perché si valuta che porti via del tempo da
dedicare invece ad altre domande. Per questo si sconsiglia di fare studi non
richiesti. Infatti:
- parti in più oltre a quelle richieste non hanno punteggio, ma gli
eventuali errori possono venir valutati;
- parti in più di una parte del compito non compensano eventuali
parti non svolte. Il punteggio delle parti non svolte non viene
comunque attribuito.
Il grafico della funzione va tracciato qualitativamente solo sulla base
degli elementi richiesti, ed è importante che sia coerente con i
risultati trovati, anche se sono sbagliati. Un grafico corretto
ma non coerente con gli errori fatti viene considerato incoerente
e penalizzato. Talvolta certi errori rendono impossibile tracciare
un grafico (per esempio, se si trova che la funzione decresce per
e contemporaneamente che diverge positivamente per
il
grafico non può farsi). In questo caso una delle informazioni
trovate è sbagliata. Se possibile, conviene correggerla. Se non c’è
tempo di correggerla, al momento di tracciare il grafico, NOTARE
ESPLICITAMENTE l’incoerenza dei risultati trovati, dicendo quali si
conservano nel tracciare il grafico. Ciò per evitare penalizzazioni dovute al
grafico incoerente. Inoltre, un compito d’esame può fare altre domande,
per esempio di individuare il numero delle intersezioni tra il grafico
tracciato e certe famiglie di curve, per esempio rette; di dedurre dal
grafico tracciato quello di altre funzioni (per esempio, dal grafico di
quello
di o
di ).
Ora commentiamo i vari passi.
-
- A) Determinazione del dominio della funzione. Ricordiamo che questo è
un problema puramente scolastico. Il dominio della funzione fa parte
della descrizione del processo fisico che si intende studiare, e quindi
è assegnato insieme alla funzione stessa. Invece, come puro esercizio
scolastico, si intende che la funzione è definita in ciascuno dei punti nei
quali possono effettuarsi le operazioni mediante le quali viene assegnata.
-
- B) Simmetrie e periodicità. Ricordiamo che una funzione è pari o dispari
se il suo dominio è simmetrico rispetto all’origine ed inoltre è pari se
(grafico simmetrico rispetto all’asse delle ordinate) ed è dispari se
(grafico simmetrico rispetto all’origine). Se una funzione è pari o dispari
ci si può limitare a studiare la funzione per
e ottenerne il grafico su tutto il dominio usandone la simmetria.
Non va dimenticato di studiare esplicitamente la natura che il punto
ha rispetto alla funzione (continuità, derivabilità, punto di estremo…).
Una funzione è periodica se esiste
tale che .
Il numero
si chiama “periodo” della funzione. Se esiste un minimo periodo
che è strettamente positivo, generalmente è tale numero che si
chiama “periodo”. Naturalmente, una funzione periodica ha dominio
illimitato sia superiormente che inferiormente ed è priva di limite per
ed ,
salvo il caso in cui sia costante. Se una funzione è periodica di periodo
,
ci si può limitare a studiarne la restrizione all’intervallo
e quindi tracciarne il grafico per periodicità (senza dimenticare di
studiare la continuità, derivabilità, massimi o minimi…in
e in ).
-
- C) Determinazione dei limiti e degli asintoti. Se il dominio è illimitato, si
calcolano i limiti per
e per .
Se uno di questi limiti è finito, e vale ,
la retta
si chiama “asintoto orizzontale” (destro, sinistro oppure bilatero). Se
invece la funzione è un infinito del primo ordine rispetto all’infinito di
confronto ,
può esistere o meno un “asintoto obliquo”. Questo va determinato. Si
calcolano quindi i punti
tali che uno almeno dei due limiti
In tal caso, la retta
si chiama “asintoto verticale” per la funzione. Ricordiamo che se
è un asintoto verticale, il punto
può appartenere o meno al dominio della funzione.
-
- D) Continuità della funzione, ed eventuali punti di discontinuità. Conviene
anche studiare se la funzione ammette o meno estensione continua a
punti che non appartengono al dominio. La funzione è continua in
se
Può accadere che
non sia definita in
ma che esista
In tal caso, la funzione
è continua in
e si chiama l’estensione per continuità di
ad .
Per esempio, la funzione
non è definita in
ma può essere estesa per continuità a
perché
Naturalmente, può accadere che si possa definire un’estensione della
funzione che è continua o solo da destra o solo da sinistra, come accade
per la funzione
Questa funzione è priva di limite per
e si ha
L’estensione
non è continua in , ma è
continua da sinistra in .
Se non è
continua in
si possono avere i tre casi seguenti:
- discontinuità eliminabile: se il limite
,
con .
Un esempio è in figura 6.2, a sinistra.
- discontinuità di prima specie o salto se ambedue i
limiti direzionali seguenti esistono finiti, ma diversi tra
loro. Non si esclude che uno dei due possa essere uguale ad
,
si veda la figura 6.2, a destra.
- discontinuità di seconda specie ogni altro caso. Esempi sono
in figura 6.3.
-
- E) Si studia la derivabilità della funzione ed eventuali punti di non derivabilità.
Supponiamo che esista, finito o meno, il limite seguente:
Si hanno i due casi seguenti:
Supponiamo ora che il limite (6.1) non esista, ma che esistano, finiti o meno,
ambedue i limiti direzionali
I due limiti si chiamano derivate direzionali (destra o sinistra) in
.
Si ha:
- se la derivata destra è finita, la funzione è continua in
da destra; analoga affermazione per la derivata sinistra. Se una
derivata direzionale è
oppure ,
la funzione può essere continua o meno.
- Se le due derivate direzionali sono ambedue finite e diverse tra loro, il punto
si dice punto angoloso e le due rette
|
|
si chiamano le tangenti al grafico di
da sinistra o da destra in
(più correttamente, sono le tangenti in
ai grafici delle restrizioni di
a ,
rispettivamente a ).
Un esempio è in figura 6.6, a sinistra.
- se la funzione è continua in
e se le due derivate direzionali in
sono una
e l’altra
, il punto
si dice cuspide
La retta
si dice ancora tangente al grafico in
.
Un esempio è in figura 6.8, a destra mentre la figura 6.6
mostra due casi in cui il rapporto incrementale ha limite
.
- Infine, supponiamo che sia
definita su un intervallo
e
(oppure ).
Se esiste la derivata, rispettivamente destra o sinistra, in
,
si può ancora parlare di tangente al grafico della funzione in
.
Naturalmente, se la derivata direzionale è
oppure
allora dovremo preventivamente richiedere che la funzione sia continua in
.
Osservazione 157 Supponiamo
definita su ,
continua in .
Supponiamo che le due derivate direzionali in
esitano e siano ambedue
oppure .
Allora,
è tangente verticale al grafico di
nel punto .
Il grafico taglia la tangente nel solo punto ,
perché la funzione è univoca. Quindi, il grafico sta da una parte
della tangente per
e dall’altra per .
Se accade che la funzione è convessa da una parte di
e concava dall’altra, il punto
si chiama flesso a tangente verticale Questo caso è illustrato nella
figura 6.6, a destra.
Lo studio della derivabilità nei punti in cui non si possono applicare le
formule di derivazione, si fa studiando esplicitamente il limite del rapporto
incrementale, generalmente mediante il Teorema di L’Hospital.
-
- F) Gli intervalli di monotonia ed i punti di estremo della funzione. Gli intervalli di
monotonia si determinano studiando il segno della derivata prima e quindi
conducono alla risoluzione di opportune disequazione. Lo studio della monotonia
può portare ad identificare immediatamente alcuni punti di estremo: quei punti
nei quali la funzione è continua e monotona di senso opposto dalle due
parti del punto. In generale, i punti di estremo della funzione vanno cercati
tra i punti in cui si annulla la derivata prima e tra i punti nei quali la funzione
non è derivabile (inclusi gli estremi del dominio, se la funzione vi è
definita). Alternativamente, invece di dedurre le proprietà di estremo dallo
studio della monotonia, si può studiare il segno delle derivate successive
(ma spesso ciò conduce a calcoli più complessi e inoltre non si
può fare negli estremi del dominio e nei punti in cui le derivate non
esistono).
-
- G) Convessità della funzione. Quando la funzione è derivabile, conviene studiare la
monotonia della derivata prima, ossia il segno della derivata seconda. Supponiamo ora
e che esista
. Confrontiamo il
grafico di con la
retta tangente in .
Si hanno tre casi:
- esiste un intorno di
in cui vale
In tal caso la funzione si dice convessa in
- esiste un intorno di
in cui vale
In tal caso la funzione si dice
concava in
La figura 6.7 mostra il grafico di una funzione che è convessa in
alcuni punti, concava in altri.
- esiste un
intorno di
tale che
|
|
(o le analoghe, con i versi delle disuguaglianze a
destra scambiati tra loro). In tal caso si dice che
è “punto di flesso”. Un esempio è in figura 6.8, a sinistra.
La figura 6.8, a destra, mostra una funzione che cambia di
concavità in corrispondenza di un punto che non è di flesso,
perché in tale punto non esiste la tangente al grafico della
funzione.
Naturalmente, può darsi che nessuno dei casi descritti si verifichi. Si
consideri l’esempio della funzione
Capitolo 7
Numeri complessi
Non è per la sua cultura che lo amo—no, non è per quello.
E’ un autodidatta; in realtà conosce una quantità di cose,
solo che non stanno cosìcome le sa lui. Diario di Eva, Il
diario di Adamo ed Eva di Mark Twain
In questo capitolo introduciamo le proprietà essenziali di una nuova classe di numeri
che si chiamano numeri complessi Per quanto storicamente falso, conviene pensare
ai numeri complessi come introdotti per risolvere l’equazione
ovviamente priva di soluzioni in .
7.1 La definizione dei numeri complessi
Si riferisca il piano ad un sistema di coordinate cartesiane
ortogonali di origine in un
punto . In questo modo, un
punto viene identificato
dalle sue coordinate
(ascissa) ed
(ordinata) e viene indicato in vari modi, per esempio
. I
numeri complessi sono i punti del piano cartesiano dotati di due operazioni che
hanno un significato fisico che vedremo, ma la notazione che si usa per indicare i
numeri complessi è diversa da quella usuale della geometria analitica o della fisica.
La seconda componente, ossia l’ordinata, si identifica mediante un “fattore”
usualmente
indicato con ,
scritta indifferentemente prima o dopo. E il punto
di
coordinate
ed si
indica con
o anche .
Questa notazione permette di identificare immediatamente l’ordinata del punto, che è
, e quindi anche
l’ascissa, che è .
Dunque, l’ordine in cui esse vengono scritte non ha influenza e lo stesso numero
complesso può rappresentarsi indifferentemente
Inoltre, se una delle due coordinate è nulla essa si sottintende e quindi
Se ambedue le coordinate sono nulle, ossia se il punto corrisponde all’origine, esso si
indica con .
Si noti in particolare: |
|
Inoltre, i numeri
si chiamano numeri immaginari (talvolta “immaginari puri”) e quindi
l’asse delle ordinate si chiama anche asse immaginario I numeri
si
chiamano numeri complessi reali e l’asse delle ascisse si chiama anche asse reale Nel
contesto dei numeri complessi, i termini “ascissa” ed “ordinata” vengono sostituiti dai
termini parte reale e parte immaginaria Inoltre, i numeri complessi si indicano spesso con
le lettere ,
,
,
ed è più frequente
usare le lettere
e (per esempio)
invece di
ed .
Ossia, scriveremo
e useremo le notazione seguenti per la parte reale e la parte immaginaria:
Si noti che “parte reale” e “parte immaginaria” sono ambedue numeri reali. Se
, il simbolo
indica il numero
che si scrive più
semplicemente .
Ossia,
L’insieme dei numeri complessi si chiama anche piano complesso o
piano di Argand-Gauss I numeri complessi si chiamano anche i “punti”
del piano complesso. Per esercizio, si indichi un numero complesso
sul piano
complesso, e quindi .
L’insieme dei numeri complessi, dotato delle operazioni che vedremo, si indica col simbolo
. La
rappresentazione
si chiama rappresentazione algebrica dei numeri complessi. E’ importante anche una
seconda rappresentazione, che si chiama “trigonometrica”.
Rappresentazione trigonometrica dei numeri complessi Consideriamo
un’altra rappresentazione dei punti del piano cartesiano, e quindi anche dei punti
del piano complesso, che si chiama la rappresentazione polare Si congiunga il punto
, ossia il numero
complesso ,
con l’origine delle coordinate. Si trova un segmento la cui lunghezza è
Il numero
si chiama il modulo del numero complesso. Il segmento fa un’angolo
con
l’asse reale positivo.
Il numero
si considera positivo se il semiasse reale positivo
gira in senso antiorario per sovrapporsi al segmento
,
orientato da
verso ;
negativo altrimenti.
Quest’angolo si chiama argomento o anomalia La coppia
si chiama rappresentazione polare ad ogni coppia
corrisponde un
solo punto .
Si noti però che la corrispondenza tra
e la sua rappresentazione polare non è biunivoca: l’angolo
è determinato a meno di multipli di
se .
Infatti,
identificano il medesimo punto .
Se ,
tutte le coppie
identificano l’origine delle coordinate. Si ritrova
una corrispondenza biunivoca, ma solamente per
,
se si impone di scegliere .
L’argomento cosìscelto si chiama argomento principale
Noti
e , si
ha
e quindi il numero complesso
si scrive come
che usa scrivere come
Si chiama questa la rappresentazione trigonometrica dei numeri complessi
7.2 Operazioni tra i numeri complessi
Per ora abbiamo descritto l’insieme dei numeri complessi. Descriviamo ora le
operazioni tra essi, che sono due: la somma e il prodotto (che daranno anche la
sottrazione e la divisione).
7.2.1 Somma di numeri complessi
E’ l’operazione di somma di vettori con la regola del parallelogramma, ossia essa si
fa sommando le componenti corrispondenti:
Si osservi che
-
-
-
- .
7.2.2 Il prodotto
Il prodotto di due numeri complessi si indica con
(o anche
semplicemente come )
e si capisce meglio rappresentando i numeri in forma trigonometrica. Definiamo
Ossia, il prodotto opera in questo modo: prima si sommano gli argomenti, e quindi
il primo punto viene ruotato di tanto quanto è l’argomento del secondo, e poi
si fa il prodotto dei moduli. Per chi conosce un po’ di elettrotecnica: è
questa la forma che assume la legge di Ohm per le correnti alternate! Il
numero
è l’elemento neutro rispetto al prodotto:
per ogni .
Il numero
deve verificare
Quindi, se ,
Definito il prodotto, si possono definire le potenze ad esponente intero:
Il prodotto in notazione algebrica Usiamo i colori per distinguere un
numero complesso dall’altro: sia
quando i due numeri sono rappresentati in notazione algebrica e, corrispondentemente
Dunque |
|
Il prodotto è: |
|
Abbiamo quindi la seguente formula per il prodotto di numeri complessi in
notazione algebrica: |
| (7.1) |
Non è necessario ricordare questa formula, perché si può ottenerla
facilmente in questo modo: distribuiamo i prodotti sulle somme, ottenendo
|
|
Ora si proceda con le usuali regole algebriche, scambiando i simbili
nei
prodotti e raccogliendoli. Si trova |
|
Confrontiamo (7.1) con (7.1). Si vede che la seconda restituisce la prima
se ad
si
sostituisce .
Infatti, con quest’ultima sostituzione si trova la formula del prodotto:
Segue da qui che le operazioni algebriche tra i numeri complessi si
fanno operando con le usuali regole algebriche, alle quali va aggiunta
l’ulteriore “regola”
7.3 Il coniugato
Sia . Il coniugato
del numero
è il numero
simmetrico di
rispetto all’asse reale. In notazione trigonometrica,
Si noti che
I numeri
e
hanno i medesimi argomenti ma in generale modulo diverso. Si ha
se e solo se ,
ossia se e solo se il punto del piano
cartesiano che corrisponde al numero complesso
è sulla “circonferenza goniometrica”, ossia sulla circonferenza di raggio
e centro l’origine delle coordinate.
Il coniugato è utile per esempio per scrivere in modo semplice l’espressione di
in
rappresentazione algebrica:
e quindi
Si verifica immediatamente che il coniugato di una somma è la somma dei
coniugati e il coniugato di un prodotto è il prodotto dei coniugati,
ossia,
Si suggerisce di verificare la regola relativa al prodotto sia usando la
rappresentazione algebrica che quella trigonometrica. Notiamo infine che se
,
7.4 Radici di numeri complessi
Ricordiamo che la radice –ma
di un qualsiasi numero
è un numero
che risolve l’equazione
Vogliamo studiare quest’equazione tra i numeri complessi. Ricordiamo il significato geometrico del
prodotto : è quel
numero il cui modulo è
ed il cui argomento è il doppio dell’argomento di
. In
generale, se
ossia, ha per
modulo e per
argomento . In
particolare, se
allora .
Dunque, l’equazione
ha la sola radice .
Sia invece
Si ricercano numeri
tali che
Quest’uguaglianza vale se e solo se ,
ossia
e inoltre
ove è un qualunque
numero intero. Dunque,
deve essere uno dei numeri
Sono questi infiniti argomenti ma, a causa della periodicità delle funzioni
e
, solamente gli argomenti
che si ottengono per ,
,
,
danno valori
diversi di .
Ricapitolando:
Geometricamente, le radici –me
di sono i vertici di un
poligono regolare di
lati, i cui vertici giacciono sulla circonferenza di centro l’origine e raggio
. La
formula (7.2) talvolta si chiama anche formula di Moivre Torniamo ora
all’uguaglianza
Uguagliando parte reale ed immaginaria di queste formule, si trovano espressioni
per e
, scritte combinando
solamente
e .
Anche queste formule si chiamano formule di Moivre Un fatto notevole
da notare è che i termini reali al membro destro devono avere
pari e in tal caso
si esprime mediante
potenze (di ordine pari) di ,
ossia
può rappresentarsi come combinazione di potenze di
, senza far
intervenire .
7.5 Esponenziale ad esponente complesso
Consideriamo un numero complesso non nullo, rappresentato in forma
trigonometrica
Dato che ,
si potrà scrivere
(con ).
Dunque avremo
Quest’uguaglianza suggerisce di definire
cosìche
Definiremo poi
cosìche
Si è cosìdefinita l’esponenziale di esponente complesso, |
| (7.3) |
Questo è niente altro che un simbolismo diverso per la rappresentazione
trigonometrica di numeri complessi. Però, l’esponenziale di numeri complessi
cosìdefinita gode delle proprietà caratteristiche dell’esponenziale reale. Infatti,
siano
e due
numeri complessi non nulli,
I moduli sono positivi e quindi si può scrivere
Dunque, il prodotto è
Si trova quindi
Ed inoltre,
Ossia, le proprietà cruciali dell’esponenziale reale continuano a valere per
l’esponenziale complesso. La (7.3) definisce una funzione che ad un numero complesso
associa un numero complesso, che si chiama l’esponenziale di numeri complessi. Le
sue proprietà essenziali sono:
- ;
- .
In particolare, l’esponenziale di numeri complessi non si annulla;
- ;
- ;
- ;
Queste proprietà sono le ovvie estensioni delle corrispondenti proprietà dell’esponenziale
di numeri reali. Le seguenti proprietà invece non hanno analogo tra i numeri reali:
- ;
- .
L’ultima proprietà mostra che l’esponenziale di numeri complessi è periodica di
periodo .
E quindi la definizione di logaritmo tra i numeri complessi, che non trattiamo, sarà
alquanto delicata. Notiamo infine le formule seguenti: |
|
L’uguaglianza
si chiama formula di Eulero La (7.3), che è la rappresentazione trigonometrica
dei numeri complessi scritta in modo più compatto, è la forma più
semplice e maneggevole quando si debbano fare operazioni di prodotto,
quoziente, potenza e radice di numeri complessi. Per questo gli si dà il nome di
rappresentazione esponenziale dei numeri complessi. Si noti che il numero
è l’unico numero complesso che non ha rappresentazione
esponenziale, ossia non si può scrivere in forma
. Infatti,
l’esponenziale non si annulla mai. Usando la rappresentazione esponenziale dei numeri complessi,
le radici -me
di
sono rappresentano come
(ed ovviamente
intero). I numeri
sono le
radici -me
di .
7.6 Continuità e derivate
Consideriamo ora una funzione a valori complessi di una variabile reale che indichiamo
con :
Supponiamo che
appartenga ad un intervallo .
Limiti e continuità si definiscono per componenti, ossia, per la definizione di
limite,
E quindi, in particolare,
è continua in
se e solo se sia
che lo
sono. La derivata si definisce come il limite del rapporto incrementale,
|
|
Dunque, anche la derivata si definisce per componenti e
è derivabile se e solo
se sono derivabili sia
che .
In tal caso si ha:
A noi interessa calcolare la derivata dell’esponenziale. Per essa vale una forma in
tutto analoga a quella che si ha per l’esponenziale reale:
Teorema 158 Vale:
Dim. Sia
Dunque,
Calcoliamo la derivata della parte reale e della parte immaginaria: |
|
Quindi: |
|
7.7 Il teorema fondamentale dell’algebra
L’esistenza delle radici permette di risolvere le equazioni della forma
ove è il
termine noto e
è l’incognita: Quest’equazione ha la sola soluzione nulla se
. Altrimenti
ammette
soluzioni. Consideriamo ora l’equazione che si ottiene uguagliando a zero un generico
polinomio
|
| (7.4) |
Se
oppure
allora quest’equazione ammette soluzioni (rispettivamente, una soluzione oppure
due soluzioni) ed esiste una formula per rappresentare le soluzioni. Formule
risolutive per le equazioni di terzo e quarto grado esistono, e sono state scoperte nel
XVI secolo. Naturalmente, in generale le soluzioni sono numeri complessi. Tra il
XVIII e il XIX secolo è stato provato che non esistono formule risolutive per
equazioni di grado superiore al quarto (espresse mediante un numero finito di
operazioni algebriche). Ciò nonostante, è stato provato il teorema seguente:
Teorema 159 (fondamentale dell’algebra) Ogni equazione di grado
ammette almeno una soluzione complessa.
Ora, si sa che se
risolve l’equazione (7.4) allora si può scrivere
ossia,
divide il polinomio. Il teorema 159 può ora applicarsi al polinomio
Se si trova
un numero
che annulla questo polinomio e che quindi risolve (7.4). Ovviamente, può accadere
che sia .
Iterando questo procedimento, si viene a scrivere
e |
| (7.5) |
I numeri , che sono
tutte e sole le soluzioni di (7.4) si dicono radici o anche zeri del polinomio e si dice che la radice
di (7.4), equivalentemente
lo zero del polinomio,
ha molteplicità ,
ove è l’esponente
del fattore .
La (7.5) vuol dire che il numero totale delle radici, ciascuna contata
secondo la propria moltaplicità, è uguale al grado del polinomio.
7.7.1 Polinomi a coefficienti reali
Ricordiamo queste proprietà dell’operazione di coniugio: il coniugato di una
somma è la somma dei coniugati e il coniugato di un prodotto è il
prodotto dei coniugati. Ossia
Dunque, .
Ricordiamo inoltre che un numero è reale se e solo se coincide col suo coniugato.
Consideriamo ora un polinomio a coefficienti reali
e supponiamo che esso si annulli in ,
Prendendo i coniugati dei suoi membri, e notando che
, si
trova
Ossia, anche
è uno zero del polinomio, che pertanto è divisibile per il trinomio a coefficienti
reali
Dunque,
Teorema 160 Sia
un polinomio a coefficienti reali e sia
un suo zero di molteplicità .
In tal caso, anche
è uno zero di ,
della medesima moltiplicità .
Di conseguenza, le radici non reali di un polinomio a coefficienti reali vengono a
coppie, e quindi esse sono in numero pari. Ricordiamo ora che il numero totale
delle radici di un polinomio è il grado del polinomio, e quindi un polinomio di
grado dispari ha un numero dispari di radici. Di conseguenza, se i coefficienti di un
polinomio di grado dispari sono reali, almeno una delle sue radici deve essere
reale:
Teorema 161 Il numero delle radici reali di un polinomio di grado dispari e
a coefficienti reali è dispari. In particolare, ogni polinomio a coefficienti reali
di grado dispari ha almeno una radice reale.
Questo risultato si è già provato in altro modo, si veda il Corollario 114.
7.7.2 Il metodo di completamento dei quadrati
E’ utile ricordare come si ottiene la formula risolutiva di |
| (7.6) |
Si nota che quest’equazione si sa risolvere se
. In questo caso le soluzioni
sono le due radici di .
Se quest’equazione può ricondursi alla forma
allora essa è ancora immediatamente risolubile,
(si ricordi che la radice nel campo complesso prende due valori, e quindi questa
espressione rappresenta due soluzioni). Mostriamo che ogni equazione
della forma (7.6) può ricondursi alla forma (7.7) mediante il metodo del
completamento dei quadrati Prima di tutto si nota che risolvere (7.6) equivale a
risolvere
Vogliamo considerare il secondo addendo come il “doppio prodotto” di
con
. Dunque sommiamo
e sottraiamo .
Si trova
E’ ora immediato vedere che l’equazione ammette due soluzioni, date da
Si noti che non abbiamo scritto
di fronte alla radice perché per definizione la radice complessa prende due valori.
In contrasto con ciò, la radice positiva di un numero reale positivo si chiama
radice aritmetica
7.8 Alcuni esercizi
- Sul piano di Argand-Gauss si segni la posizione di un numero complesso
.
Si segnino quindi i punti della lista seguente:
|
|
Si consideri in particolare il caso in cui
giace su uno dei quattro semiassi coordinati.
- Sia ,
. Calcolare
.
chi conosce le espressioni in coordinate cartesiane ortogonali del prodotto
scalare e del prodotto vettoriale, noti come queste si ritrovano in questo
prodotto.
- Siano e
. Si identifichi
la posizione di
e
sul piano complesso, e si rappresentino i due punti
e
.
- Si calcolino i numeri
per intero
compreso tra
e .
- Usando la formula del binomio di Newton, si calcoli
.
Si scriva quindi la rappresentazione trigonometrica del numero
e si usi questa
per calcolare .
Rappresentare questo numero sul piano di Argand-Gauss.
- I numeri complessi ,
abbiano
modulo e
inoltre abbia
argomento
mentre abbia
argomento .
Sul piano complesso, si individui il punto
. Si vuol sapere
se esiste
tale che
e, nel caso affermativo, la sua posizione sul piano complesso.
- Si consideri un quadrato sul piano complesso, inscritto nella circonferenza
trigonometrica e i cui lati sono paralleli agli assi coordinati oppure alle
bisettrici degli assi. Si vuol sapere se i suoi vertici sono o meno radici di un
certo ordine di qualche numero.
- Il numero complesso
abbia moduli ed
argomento . Calcolare
un numero di cui
è radice quarta. Quanti sono tali numeri?
- Scrivere in forma trigonometrica il numero
.
- ()
Rappresentare sul piano di Argand-Gauss i numeri
e notare che essi si trovano su un numero finito di rette uscenti
dall’origine. Dire se accade un fatto analogo per i numeri
e
.
- () Si mostri che vale
l’uguaglianza . Si consideri
quindi l’uguaglianza .
Dire se quest’uguaglianza è corretta. In generale discutere l’uguaglianza
.
- Rappresentare sul piano complesso i numeri
per
. E se invece si
considerano i numeri ?
- rappresentare sul piano di Argand-Gauss l’immagine della trasformazione
.
- Calcolare le derivate prima e seconda della funzione
e rappresentare sul piano di Argand-Gauss sia
che
ed
.
- () Scrivere la formula
di McLaurin di
e sostituire ad
ad .
Trovare le relazioni tra la formula ottenuta e le formule di McLaurin di
e
(si ottiene una prima versione della “most remarkable formula in
mathematics”, come si esprime R. Feyman, nelle Feyman Lectures on
Physics).
- ()
Sia ,
. Dire se,
fissati ed
, esitono
valori di
e tali
che per
ogni
(è possibile cancellare un suono mediante un altro suono? Si calcolino le
parti reali).
- ()
Sia ,
. Calcolare la
parte reale di .
Si riesce a scriverla in modo da vedere una relazione col fenomeno dei
battimenti?
- () si consideri
la funzione .
Se ne rappresenti il valore sul piano complesso per ogni valore di
. Si trova
un vettore applicato nell’origine, ruotante (in quale verso?) al crescere del tempo
. Si riesce ad
interpretare
facendo intervenire il moto armonico?
Capitolo 8
Equazioni differenziali
Ebbi dunque il mio relatore, tanto coscienzioso quanto
ben disposto; si lasciò sfuggire qualche lacuna nelle
dimostrazioni, però mi diede utili consigli sulle virgole.
André Weil, Ricordi di apprendistato, vita di un matematico
In questo capitolo studiamo tre tipi di equazioni differenziali, ossia equazioni in cui
l’incognita è una funzione, e che coinvolgono, insieme alla funzione incognita,
anche le sue derivate.
ATTENZIONE
Nello studio delle equazioni differenziali è cruciale questo risultato,
provato al Teorema 195: ogni funzione continua su un intervallo
ammette primitive.
8.1 Introduzione
Le equazioni differenziali sono un argomento importantissimo in tutte le
applicazioni della matematica, e molto vasto. Noi ci limitiamo a studiare le
equazioni differenziali di tre classi particolari, che ora descriviamo. Diciamo
però prima di tutto che, a differenza delle equazioni studiate fino ad ora,
l’incognita da determinare quando si “risolve” un’equazione differenziale
è una funzione derivabile. Le applicazioni fisiche richiedono che tale
funzione sia definita su un intervallo. Le equazioni differenziali che
studieremo hanno infinite soluzioni. Le applicazioni alla fisica richiedono di
identificare tra tutte le soluzioni una (o più) che soddisfano certe condizioni
accessorie. Noi ci limiteremo a considerare delle condizioni accessorie dette
condizioni iniziali o anche condizioni di Cauchy Vedremo che la soluzione che
verifica queste condizioni è unica se valgono opportune ipotesi usualmente
soddisfatte nelle applicazioni. Descriviamo ora le equazioni differenziali che
studieremo.
Equazioni a variabili separabili. Le equazioni a variabili separabili sono equazioni
differenziali del primo ordine ossia equazioni in cui compare, insieme alla funzione
incognita ,
anche la sua derivata prima (ma non compaiono derivate successive). Eventualmente
dopo opportune manipolazioni, le equazioni a variabili separabili si riconducono alla
forma seguente: |
| (8.1) |
La proprietà essenziale è che la funzione
non dipende
esplicitamente da
mentre la funzione non
dipende da . Per esempio,
l’equazione differenziale
NON è un’equazione a variabili separabili.
Definizione 162 Una funzione
si chiama soluzione dell’Eq (8.1) se ha le seguenti proprietà:
- è definita su un intervallo apero
(limitato o meno);
- è di classe ;
- sostituita nei due membri di (8.1) verifica l’uguaglianza per ogni
.
Osservazione 163 (IMPORTANTE)
- Come si è detto, la funzione
da determinare deve essere definita su un intervallo. Un’equazione a
variabili separabili (con
e
continue) ammette infinite soluzioni. E’ importante notare che soluzioni
diverse della medesima equazione differenziale possono essere
definite su intervalli diversi.
- la variabile indipendente è stata indicata con la lettera
perché in pratica indica il tempo. Però la stessa equazione differenziale
potrebbe essere scritta con lettere diverse, per esempio
In questo caso la variabile “tempo” si è indicata con la lettera
.
- La forma (8.1) in cui abbiamo scritto l’equazione differenziale è
corretta, ma generalmente non usata. Di regola non si indica la
dipendenza della soluzione dalla variabile “tempo” e la (8.1) si scrive
usualmente in forma
E’ importante tener conto di ciò per esempio quando si vuol calcolare la
derivata seconda di ,
che va calcolata usando la regola di derivazione della funzione composta:
|
|
- La funzione
potrebbe essere costante. In questo caso, inglobando la costante nella funzione
,
l’equazione differenziale prende forma
e si chiama autonoma o tempo invariante
Il problema di Cauchy per la (8.1) consiste nel trovare la soluzione o le soluzioni che verificano la
condizione accessoria
ove
ed
sono assegnati. Ossia si chiede di determinare una soluzione il cui grafico contiene il
punto .
Convenzionalmente,
si chiama istante iniziale e il problema di Cauchy si chiama anche
problema ai dati iniziali Il problema di Cauchy per la (8.1) si scrive
Vedremo che se
è una funzione di classe
mentre
è continua, il problema di Cauchy ammette
soluzione unica, definita in un intorno di
.
Equazioni differenziali lineari del primo ordine. Le equazioni differenziali
lineari del primo ordine sono sono le equazioni
usualmente scritte
La funzione
si chiama il coeffciente dell’equazione differenziale (lineare del primo ordine) mentre
si chiama il termine noto
Assumeremo che
ed siano
continue.
L’equazione differenziale del primo ordine si dice a coeffciente costante quando
è costante e si chiama
omogenea quando .
Quando
l’equazione si dice completa o anche affne Data l’equazione affne (8.2), la sua
equazione omogenea associata è
Notiamo che un’equazione differenziale lineare omogenea del primo ordine
è anche un’equazione differenziale a variabili separabili. Per definizione,
è una soluzione dell’equazione differenziale (8.2) se è di classe
su un
intervallo
e se, sostituita nell’equazione, verifica l’uguaglianza per ogni
. Il
problema di Cauchy per la (8.2) consiste nel cercare la soluzione che soddisfa la condizione accessoria
, ossia il cui grafico
contiene il punto .
Esso si scrive
Vedremo che nel caso delle equazioni lineari
con coefficienti e termini noti continui su
,
il problema di Cauchy ammette una ed una sola
soluzione. Questa affermazione è analoga a quella fatta per
le equazioni differenziali a variabili separabili, ma c’è una
differenza importante: Nel caso delle equazioni differenziali
lineari, le soluzioni del problema di Cauchy sono definite su
.
Nel caso delle equazioni a variabili separabili in
generale il dominio è un intervallo (diverso da
)
anche se il membro destro è definito per ogni
e per ogni .
Equazioni differenziali lineari del secondo ordine. Sono le equazioni di
forma |
| (8.3) |
In quest’equazione, si chiama
il termine noto o forzante e ,
si
chiamano i coefficienti. Noi studieremo solamente le equazioni differenziali lineari
del secondo ordine a coefficienti costati, mentre il termine noto potrà essere
costante o meno. Ancora, l’equazione si dice omogenea se il termine noto è nullo; si
dice affne o completa altrimenti; e l’equazione lineare omogenea del secondo ordine
associata alla ( 8.3) è
Per definizione,
è una soluzione dell’equazione differenziale (8.3) se è di classe
su un
intervallo
e se, sostituita nell’equazione, verifica l’uguaglianza per ogni
. Nel
caso delle equazioni differenziali del secondo ordine, il problema di Cauchy consiste
nel risolvere
Ossia, si richiede una soluzione che in un istante
ha il
valore
e anche tale che la sua derivata nel medesimo istante
vale
.
Geometricamente, si cerca una soluzione il cui grafico passa per il punto
e che, in tale punto ha
tangente di pendenza .
Convenzionalmente, l’istante
si chiama ancora istante iniziale Ricordando l’interpretazione della derivata come
velocità istantanea, il problema di Cauchy consiste nel trovare una traiettoria
che ad un certo
istante passa
per la posizione
con velocità .
Anche nel caso delle equazioni differenziali lineari
del secondo ordine, con termine noto definito su
,
le soluzioni sono definite su .
Osservazione 164 Consideriamo il problema
Questo non è un problema di Cauchy perché non impone alcuna
condizione alla velocità iniziale, ed ammette infinite soluzioni: una soluzione
per ciascuna condizione che si ottiene assegnando anche il valore di .
Analogamente, il problema ,
non è un problema di Cauchy.
8.2 Soluzione delle quazioni differenziali a variabili separabili
Ricordiamo che queste sono le equazioni della forma |
| (8.4) |
Le funzioni
e
sono continue (più avanti richiederemo la derivabilità di
).
Studiamo prima come trovare tutte le soluzioni dell’equazione, e poi come trovare le
soluzioni del problema di Cauchy |
| (8.5) |
Il primo passo nella ricerca delle soluzioni consiste nel ricercare le
eventuali soluzioni costanti. Un’equazione a variabili separabili
può ammettere o meno soluzioni costanti. Naturalmente, se
oppure
l’equazione si riduce a
e le sue soluzioni sono tutte e sole le funzioni costanti. Le funzioni definite su un
intervallo e costanti, sono tutte e sole quelle con derivata nulla. Dunque, le soluzioni
che
risolvono la (8.4) sono quelle per cui vale
Ciò accade se il numero
è uno zero della funzione .
Si ha quindi:
Primo passo della ricerca di soluzioni: si risolve l’equazione
Se il numero
risolve quest’equazione, allora la funzione costante
è soluzione di ( 8.5).
Ora ricerchiamo soluzioni non costanti. Se
per un
valore ,
la disuguaglianza continua a valere in un intorno di
, grazie
al teorema di permanenza del segno per le funzioni continue. Dunque, in un intorno
di si
può scrivere |
| (8.6) |
Le due funzioni
sono continue. Dunque ammettono primitive
ed
.
Ricordando la formula per la derivata delle funzioni composte, si vede che la (8.6)
è niente altro che
Abbiamo cosìdue funzioni della variabile
,
definite sul medesimo intervallo e con la medesima derivata. Dunque, la
differenza di queste due funzioni è costante: |
| (8.7) |
Quest’espressione si chiama integrale primo o integrale generale dell’equazione a
variabili separabili. Ogni soluzione non costante dell’equazione si trova assegnando
a
un opportuno valore. E’ anche possibile che certi valori di
portino ad identificare soluzioni costanti, ma ciò non è garantito
perché il procedimento che abbiamo fatto (in particolare la divisione per
) non è
lecito se
è una soluzione costante.
8.2.1 Problema di Cauchy per le equazioni differenziali a variabili
separate
Consideriamo ora il problema di Cauchy (8.5) e ricerchiamo condizioni perché
esso ammetta soluzioni, e perchè la soluzione sia unica. Vale il seguente
Teorema 165 (Teorema di Cauchy) Se la funzione
è continua in un intorno di
e se la funzione
è continua in un intorno di ,
il problema di Cauchy (8.5) ammette soluzione, definita in un opportuno
intorno di .
Se inoltre
è di classe ,
la soluzione è unica.
Per trovare esplicitamente la soluzione, dobbiamo prima di tutto
controllare se la soluzione richiesta è costante, cosa che accade se
. Altrimenti,
dobbiamo sostituire
ed
nei due membri di (8.7). Ciò identifica il valore della costante
.
Ossia, si deve scegliere
Ciò fatto, per ogni
si risolve rispetto ad
l’equazione
Osservazione 166 Se ,
la funzione continua
ha segno costante in un intorno di
cosìche
è ivi continua e strettamente monotona. Infatti, la sua derivata
ha segno costante. Dunque l’immagine di
è un intervallo
che contiene .
Per
“vicino” a ,
avremo ,
perché anche
è continua Essendo strettamente monotona,
è invertibile. L’unica soluzione
del problema (8.7), e quindi del problema di Cauchy, è data da
ed è definita per ogni
in un opportuno intorno di .
Però non è detto che sia sempre possibile esprimere questa funzione
mediante funzioni elementari. Spesso dovremo contentarci dell’espressione
implicita (8.7) e della determinazione del valore .
Il significato geometrico del teorema 165 va capito bene: esso asserisce che, se
è continua
ed è
derivabile, i grafici di soluzioni diverse della medesima equazione differenziale non
si intersecano. La figura 8.1 mostra, in azzurro, i grafici di alcune soluzioni
dell’equazione differenziale
Il grafico in rosso interseca le soluzioni dell’equazione differenziale e quindi
non è grafico di una soluzione di (8.8).
Osservazione 167 Si sa, dalla tavola delle derivate fondamentali, che
Quindi, la funzione
risolve il problema di Cauchy
Il Teorema 165 garantisce che non ci sono altre funzioni che verificano queste
condizioni. Infatti, il secondo membro
è funzione derivabile di .
Vediamo ora un’applicazione del Teorema 165, che conduce a risolvere un’equazione
differenziale lineare omogenea del primo ordine.
Esempio 168 Sia
una funzione continua e consideriamo l’equazione differenziale
Vogliamo trovarne tutte le soluzioni. Come sempre quando si studiano
equazioni a variabili separabili, se ne cercano prima di tutto le soluzioni
costanti. In questo caso l’unica soluzione costante è .
Se
è una soluzione non costante, essa rimane o sempre positiva o
sempre negativa. Infatti, essendo continua e definita su un intervallo, se
cambiasse segno dovrebbe annullarsi in un certo istante
e quindi
sarebbe una soluzione non costante del problema di Cauchy
Cioè, questo problema avrebbe sia la soluzione non costante
che la soluzione identicamente nulla. Il Teorema 165 mostra che ciò non può
essere, e quindi che
non si annulla: o prende valori solamente positivi
oppure prende valori solamente negativi. Dunque, possiamo dividere per
ottenendo
Sia ora
una primitiva di .
Allora vale
Il numero
è qualsiasi e quindi il numero
è un numero positivo qualsiasi:
Ma,
ha segno costante, e quindi abbiamo
per ogni vale oppure .
Dunque avremo
In definitiva,
con
reale qualsiasi, non nullo. Si noti che la soluzione
non si è ritrovata.
Però, noi sappiamo che
è una soluzione dell’equazione e quindi possiamo permettere a
di prendere
il valore ,
trovando |
| (8.9) |
come espressione di tutte le soluzioni.
Si noti il ruolo particolare delle soluzioni costanti: talvolta queste non si ritrovano
nell’integrale generale. Può essere possibile farvele comparire forzando la
costante ad assume dei valori che non potrebbe assumere. Talvolta invece ciò
non può farsi. Per questa ragione, le soluzioni costanti si chiamano anche
soluzioni singolari Un’altra applicazione importante del Teorema 165 è che
spesso permette di tracciare qualitativamente il grafico delle soluzioni,
senza risolvere l’equazione differenziale, come mostra l’esempio seguente:
Esempio 169 Consideriamo l’equazione differenziale
Il Teorema 165 permette immediatamente di concludere che le soluzioni sono
tutte funzioni limitate. Infatti, quest’equazione ha infinite soluzioni costanti,
che “affettano” il piano in strisce parallele:
Ovviamente queste soluzioni sono limitate. Sia
un’altra soluzione. Il punto
del suo grafico starà in una striscia
Il grafico della soluzione non può uscire da questa striscia altrimenti, per
il teorema dei valori intermedi, dovrebbe intersecare il grafico di una delle
soluzioni costanti; e ciò non può essere per il Teorema 165. In realtà può
dirsi anche di più: consideriamo una soluzione il cui grafico sta nella striscia
(le altre strisce si trattano in modo analogo). In questa striscia,
e quindi avremo
Dunque, una soluzione
(il cui grafico è in questa striscia) decresce per
e per .
In particolare,
è punto di minimo ed
è punto di massimo delle soluzioni. Note queste informazioni, non è diffcile
disegnare qualitativamente il grafico della soluzione. I grafici di alcune soluzioni
sono in figure 8.2.
Infine, consideriamo l’esempio seguente, che mostra che il problema di
Cauchy (8.5) in generale ha più soluzioni, ovviamente quando la funzione
non è
di classe :
Esempio 170 Si consideri il problema di Cauchy
Ovviamente,
risolve questo problema. Si verifichi che anche la funzione
risolve il medesimo problema di Cauchy.
8.2.2 Domini massimali di soluzione
Per definizione, il dominio di una soluzione di un’equazione differenziale deve essere
un intervallo (limitato o meno). Può venire il dubbio che nel caso in cui il membro
destro di un’equazione a variabili separabili sia regolare il dominio debba essere
. E’
importante sapere che ciò è falso.
Esempio 171 Consideriamo il problema di Cauchy
Ricordando che
si vede immediatamente che la soluzione di questo problema di Cauchy è
definita sull’intervallo
La soluzione ha per dominio un intervallo limitato, nonostante il fatto che il
secondo membro dell’equazione non dipenda esplicitamente da ,
e sia una funzione di classe .
Il dominio della soluzione cambia al variare di ,
e questo è ovvio; ma, fissato il valore di ,
cambia anche al variare di .
Naturalmente, una soluzione definita su un intervallo
è anche soluzione su
qualsiasi sottointervallo .
L’interesse di quest’osservazione si vede leggendola al
contrario: può essere che si riesca ad identificare un intervallo
su cui
la soluzione è definita, ma che questo non sia il massimo intervallo su cui la
soluzione è definita. Tale massimo intervallo si chiama dominio massimale
della soluzione. E’ molto facile verificare se un intervallo su cui abbiamo
trovato una soluzione è dominio massimale o meno. Torniamo a considerare
le soluzioni dell’equazione dell’Esempio 171. Queste divergono per
tendente agli estremi dell’intervallo su cui sono definite. Ciò avviene sempre:
Teorema 172 Si consideri l’equazione differenziale
Supponiamo che
sia continua su
e che
sia derivabile (e quindi continua) su .
Consideriamo la soluzione che verifica
Sia
il dominio massimale della soluzione e sia .
Allora,
Proprietà analoga vale per
se .
Di conseguenza:
- se troviamo una soluzione definita su
con
e che non diverge per
tendente ad uno dei due estremi dell’intervallo, questo intervallo non è
il dominio massimale della soluzione;
- le soluzioni dell’equazione differenziale dell’Esempio 169, essendo limitate,
sono definite su .
Una soluzione definita su può
avere limite o meno per
oppure per .
Per tracciare qualitativamente il grafico di soluzioni di equazioni differenziali, è
utile conoscere il risultato seguente:
Teorema 173 Sia
una funzione di classe
e consideriamo un’equazione differenziale del primo ordine autonoma
Sia
una sua soluzione definita su una semiretta. Se
Allora,
Ossia, le soluzioni di equazioni differenziali autonome del primo
ordine, con secondo membro regolare, se ammettono limite per
oppure
,
convergono al valore di una soluzione costante.
8.3 Le equazioni differenziali lineari
La seconda classe di equazioni che vogliamo trattare è quella delle equazioni
differenziali lineari, limitandoci ai casi:
- equazioni differenziali lineari del primo ordine
col coeffciente
e termine noto
funzioni anche non costanti (assumeremo continue, ma basta che siano
dotate di primitiva anche in senso generalizzato);
- equazioni differenziali lineari del secondo ordine a coefficienti costanti
con
e
costanti (mentre
non è costante; assumeremo per semplicità che sia continua, ma basta
che sia dotata di primitiva anche in senso generalizzato). Il metodo che
vedremo per le equazioni del secondo ordine si applica anche ad equazioni
differenziali lineari di ordine più alto, purché a coefficienti costanti:
8.3.1 Equazioni differenziali lineari del primo ordine
Studiamo l’equazione |
| (8.10) |
Ricordiamo che quest’equazione si dice completa o affne se
e che
l’equazione differenziale lineare omogenea ad essa associata è quella che si ottiene
ponendo ,
ossia è
Questa è un’equazione a variabili separabili e si è già risolta all’Esempio 168.
Ogni sua soluzione ha forma
ove è una qualsiasi
primitiva di . Se vogliamo
la soluzione che verifica
sceglieremo
Nel caso particolare in cui è
costante, una delle primitive è
e quindi le soluzioni sono
Risolviamo ora l’equazione completa. Presentiamo i calcoli nel caso in cui
è
costante. In modo del tutto analogo troveremo la soluzione anche nel caso del
coeffciente variabile. Prima di tutto scriviamo la (8.10) come
Poi moltiplichiamo i due membri per :
L’espressione a sinistra è la derivata di un prodotto e quindi si ha:
Dunque, una primitiva del membro destro e una del membro sinistro differiscono
per una costante (ricordiamo che stiamo lavorando su un intervallo):
ossia
ove è un qualsiasi
numero reale. Quando
calcoli del tutto analoghi portanto a trovare la formula seguente per la soluzione. In questa formula,
è una qualsiasi
primitiva di : |
| (8.12) |
Osserviamo ora questa formula, notando in particolare due fatti importanti.
La formula (8.12) mostra che
è somma di due addendi. Il primo è
Al variare della costante arbitraria
quest’addendo dà tutte le soluzioni dell’equazione differenziale lineare
omogenea associata. Il secondo è |
| (8.13) |
Questa è una particolare soluzione dell’equazione completa (quella che si annulla
per ).
Dunque: l’integrale generale di (8.10) si ottiene scegliendo una soluzione particolare
dell’equazione (8.10) stessa e sommandogli tutte le soluzioni dell’omogenea
associata (8.11).
Se accade che il termine affne è combinazione lineare di due funzioni
allora
si ricordi la proprietà di linearità del calcolo delle primitive. Dunque, quando il
termine noto è somma di funzioni più semplici, per trovare una soluzione
particolare si possono trovare soluzioni particolari corrispondenti ai singoli addendi,
e poi sommarle. Introduciamo ora i termini seguenti: il membro destro di (8.12) si
chiama integrale generale di (8.10) mentre la funzione in (8.13) si chiama
integrale particolare di (8.10). Ciò che abbiamo notato è particolarmente
importante, e vale la pena di evidenziarlo:
Per trovare l’integrale generale dell’equazione completa (8.10) si
calcola, in qualunque modo, anche semplicemente per tentativi, una
soluzione particolare dell’equazione (8.10) stessa e le si sommano tutte
le soluzioni dell’omogenea associata (8.11). Quando il termine noto è
somma di più addendi, una soluzione particolare si trova ricercando
soluzioni particolari relative ai singoli addendi, e quindi sommandole.
8.3.2 Problema di Cauchy per le equazioni differenziali lineari del primo
ordine
Ricordiamo che il problema di Cauchy per le equazioni differenziali lineari del primo
ordine è il problema |
| (8.14) |
Supponiamo che
sia definita su .
Allora, questo problema ammette soluzione unica, definita su
. Essa
si ottiene imponendo l’uguaglianza
In particolare, se si è scelto
e come primitiva
quella che si annulla in ,
basta scegliere .
Ciò completa quanto si può dire in generale sull’equazione differenziale lineare
del primo ordine. Però in pratica è importantissimo saper trattare col minimo di
calcoli alcuni casi particolari, che ora andiamo a vedere. Si tratta di equazioni
col coeffciente costante e termine noto di tipo particolare, che si incontra
frequentemente nelle applicazioni alla fisica.
Casi particolari di equazioni differenziali lineari del primo ordine, a coefficienti
costanti
Vogliamo dare dei metodi semplici per calcolare una soluzione particolare
dell’equazione
(con coeffciente costante)
quando il termine noto
ha forma particolare. Esaminiamo i casi che interessano:
Il caso ed
In questo caso, si ricerchi
una soluzione di forma ,
costante. Sostituendo nei due membri dell’equazione si vede che deve essere
Dunque, se ,
costante, una soluzione particolare è
La forma esplicita della soluzione non va ricordata, nè in questo caso
né nei successivi. Bisogna invece capire il procedimento in modo da
poterlo usare correttamente, ricavando volta per volta l’espressione
della soluzione particolare.
Il caso
ed Si
ricerchi una soluzione di forma
Sostituendo nei due membri dell’equazione si vede che deve aversi
Il caso polinomio
ed Procedendo
per sostituzione, come nei casi precedenti, si vede che una soluzione è un polinomio dello
stesso grado di .
Il caso
ed .
In questo caso l’equazione è
e le sue soluzioni si ottengono semplicemente calcolando primitive,
. Conviene però
cercare di procedere come nei casi precedenti, per capire meglio il metodo. In questo caso,
non risolve l’equazione
completa, infatti,
risolve l’equazione omogenea. Sostituendo si trova infatti
e l’uguaglianza non può valere. Però, se si prova a sostituire
si trova
e ora l’uguaglianza vale con .
Ossia in questo caso la soluzione è un polinomio, di grado
invece che
di grado .
Il caso polinomio
ed Procedendo
come sopra, si vede che una soluzione particolare è un polinomio, di grado
se il termine
noto ha
grado . I
coefficienti del polinomio si ricavano sostituendo nei due membri e richiedendo che i
due membri siano uguali (alternativamente ed in modo più semplice, calcolando le
primitive dei due membri).
Il caso
con In
questo caso, una soluzione particolare ha forma
come si vede immediatamente sostituendo nei due membri dell’equazione.
Il caso
con In
questo caso,
risolve l’equazione omogenea associata, e quindi non può risolvere l’equazione
completa. Infatti, sostituendo si trova
uguaglianza ovviamente falsa. Una soluzione particolare però si trova
scegliendo
come si vede immediatamente sostituendo nei due membri dell’equazione.
Il caso
con
polinomio.Vanno esaminati separatamente due casi:
-
caso :
-
una soluzione particolare dell’equazione completa è
ove
è un polinomio dello stesso grado di .
-
caso :
-
una soluzione particolare dell’equazione completa è
ove è un
polinomio di grado
se è il
grado di .
I coefficienti del polinomio si ricavano sostituendo nei due membri e
richiedendo che i due membri siano uguali.
Nei casi particolari precedenti, un’attenzione
particolare è necessaria quando il temine forzante
ha forma ,
con
polinomio ed
soluzione dell’equazione differenziale lineare omogenea associata (e
quindi
multiplo di ).
In tal caso una soluzione particolare ha forma
ove
è un polinomio il cui grado supera di
quello di .
Osservazione 174 Quest’osservazione semplifica un po’ i calcoli nel caso
:
il termine costante
del polinomio
conduce a
che è una soluzione dell’equazione lineare omogenea associata e quindi
possiamo limitarci a lavorare con polinomi
privi di termine costante; ossia, possiamo sostituire la (8.15) con
con
polinomio dello stesso grado di .
Notiamo ciò che hanno in comune i casi particolari precedenti: il termine noto appartiene ad
un insieme
di funzioni, che gode di questa proprietà: le derivate di elementi di
sono ancora elementi dell’insieme; e inoltre, moltiplicando elementi di
si trovano altri
elementi di .
L’insieme
con ,
non ha questa proprietà di invarianza, perché la derivata di
è
. Però,
l’insieme
(con
e
reali qualsiasi) gode della proprietà detta sopra. E quindi:
Il caso In
questo caso una soluzione particolare è
come si vede sostituendo nell’equazione: per avere una soluzione, l’uguaglianza seguente deve
valere per ogni :
Ciò accade se
In modo analogo si tratta il caso
ed i casi in cui il termine noto è combinazione lineare di polinomi moltiplicati per
seni e coseni.
8.3.3 L’equazione differenziale lineare del secondo ordine
Premettiamo un’osservazione importante sull’equazione differenziale lineare
omogenea del primo ordine, a coeffciente costante:
Si è già notato che le soluzioni dell’equazione
sono tutte e sole le funzioni .
Qui,
è costante. L’osservazione che ci interessa è che sia
che la costante
possono essere sia reali che complessi, si veda il paragrafo 7.6.
Consideriamo ora le soluzioni di
con ,
e
numeri complessi ed diverso da .
Un calcolo analogo a quello fatto nel caso reale mostra che le soluzioni
sono le funzioni
(sostituendo nell’equazione si trova
).
Passiamo ora a capire come sia possibile risolvere equazioni lineari del secondo
ordine, a coefficienti costanti, omogenee o meno. Per questo indichiamo con
l’operazione di fare la derivata e consideriamo un’equazione data in questa forma |
| (8.16) |
Spieghiamo cosa si intende con questa notazione. Con
intendiamo
A quest’espressione applichiamo ,
ossia |
|
Dunque, la (8.16) è niente altro che l’equazione di secondo ordine |
| (8.17) |
Come risolvere la (8.16) è immediatamente evidente. Si introduca il simbolo
per
indicare la funzione (ancora incognita)
Allora, la funzione
deve risolvere l’equazione differenziale
equazione che sappiamo risolvere. Calcolata
, la
soluzione
di (8.16) si ottiene semplicemente risolvendo
Questi sono calcoli che già sappiamo fare, con
,
sia
reali che complessi. Ma ora, se l’equazione da risolvere è data nella forma |
| (8.20) |
si sa come ridurla alla forma (8.16): si risolve l’equazione
ottenendo le due soluzioni
ed ,
che saranno numeri reali oppure complessi. Si sa che queste soluzioni verificano
e quindi la (8.20) è niente altro che la (8.16), con questi numeri
ed
; e
quindi si sa come risolvere tutte le equazioni differenziali lineari a coefficienti
costanti, del secondo ordine. In questo contesto, l’equazione (8.21) si chiama
l’equazione caratteristica dell’equazione differenziale e le sue soluzioni si chiamano
autovalori dell’equazione differenziale.
Si ricordi che se i coefficienti
e
sono reali, gli autovalori possono essere sia reali che complessi, coniugati
l’uno dell’altro.
Osservazione 175 Si parla di “equazione caratteristica” ed “autovalore”
anche nel caso delle equazioni lineari del primo ordine. Nel caso di ,
l’equazione caratteristica è
e l’unico autovalore è .
In particolare, è reale se il coeffciente è reale.
E’ del tutto ovvio che un metodo di fattorizzazione analogo si possa applicare a tutte le
equazioni differenziali lineari a coefficienti costanti, di qualsiasi ordine.
A noi non interessa scrivere esplicitamente una formula per le soluzioni
dell’equazione (8.20). La (8.20) in generale si risolve risolvendo prima la (8.18) e
poi la (8.19). Interessa piuttosto conoscere il risultato seguente, che è
semplice conseguenza dei fatti 1–3 studiati per le equazioni del primo ordine:
Oltre a questo fatto, interessa:
- saper risolvere con prontezza i casi particolari che si incontrano più
frequentemente nelle applicazioni;
- saper trovare soluzioni reali nel caso in cui gli autovalori siano numeri
complessi e coniugati.
Casi particolari di equazioni differenziali lineari del secondo ordine,
omogenee
Esaminiamo i seguenti casi, che si risolvono applicando i metodi visti per le
equazioni lineari del primo ordine con termine noto di tipo particolare.
Caso 1: autovalori reali e distinti. In questo caso, risolvendo una dopo
l’altra le due equazioni del primo ordine (8.18) e (8.19), si vede che l’integrale
generale dell’equazione è
con e
arbitrari numeri reali.
Caso 2: autovalori coincidenti. Sia
il
valore comune degli autovalori In questo caso, risolvendo una dopo l’altra le due
equazioni del primo ordine (8.18) e (8.19), si vede che l’integrale generale
dell’equazione è
con e
arbitrari numeri reali. Si noti il caso particolare in cui
. In
questo caso la soluzione generale è
Caso 3: autovalori complessi e coniugati. In questo caso gli autovalori
sono distinti e quindi, risolvendo una dopo l’altra le due equazioni del primo
ordine (8.18) e (8.19), si vede che l’integrale generale dell’equazione è |
| (8.22) |
con e
arbitrari numeri che ora potranno essere o reali o complessi. Nella maggior
parte delle applicazioni i coefficienti dell’equazione sono reali e quindi
ed
sono
tra loro coniugati
In tal caso, la (8.22) prende forma
Se e
sono
numeri complessi qualsiasi, queste soluzioni prendono valori complessi.
Spesso interessa identificare quelle che prendono valori reali. Dato che
ed
sono tra loro coniugate, ciò si ottiene scegliendo anche
e
tra
loro coniugati:
Con questa scelta si trova
Nei corsi di fisica si preferisce scrivere quest’espressione in una forma diversa.
Prima di tutto questa si scrive
I numeri
sono le coordinate di un punto della circonferenza trigonometrica e quindi esiste un
angolo
tale che
Dunque, |
| (8.23) |
In quest’espressione,
è un numero non negativo arbitrario. Anche
è un numero arbitrario ma naturalmente basta scegliere
. Quando
la soluzione
è scritta in forma (8.23), si usa la seguente terminologia:
- il numero
si chiama ampiezza
- il numero
si chiama fase
- il numero
si chiama frequenza angolare
- il numero
(notare il segno!) si chiama costante di tempo del sistema.
Casi particolari di equazioni differenziali lineari del secondo ordine complete
Nel caso affne, le soluzioni si trovano risolvendo a catena le due equazioni
differenziali del primo ordine (8.18) e (8.19), con calcoli che sappiamo già fare.
Consideriamo esplicitamente i casi in cui il termine noto ha forma particolare, e
ricerchiamo soluzioni particolari dell’equazione. A queste, per ottenere la
soluzione generale, dovremo aggiungere tutte le soluzioni dell’equazione differenziale
lineare omogenea associata. ossia
SOMIGLIANZA col caso del primo ordine: ricercheremo soluzioni particolari di forma
, con
polinomio
di grado ,
se
non è autovalore dell’equazione; altrimenti ricercheremo soluzioni di forma
se
è autovalore
semplice oppure se
è autovalore doppio.
In ambedue i casi,
ha grado
(si veda l’Osservazione 174 per spiegare l’assenza del termine di grado
e, nel caso dell’autovalore doppio, anche di grado
).
DIffERENZA rispetto al caso del primo ordine: il procedimento
per la ricerca della soluzione particolare ora va fatto due volte, una per
l’equazione (8.18) e una seconda volta per (8.19). Ciò spiega perché è possibile
che il grado debba essere aumentato di due unità invece che di una.
- il caso
oppure
con
polinomio di grado .
Nel caso delle equazioni del primo ordine (a coefficienti reali)
non
è mai un autovalore dell’equazione e quindi queste funzioni non sono mai
soluzioni dell’equazione; e quindi si ricerca una soluzione particolare in forma |
| (8.24) |
con e
polinomi ancora
di grado .
SOMIGLIANZA col caso del primo ordine: anche nel caso dell’equazione
lineare del secondo ordine si ricerca una soluzione di questa stessa forma (8.24) se
non è autovalore
dell’equazione;
DIffERENZA rispetto al caso del primo ordine: nel caso del secondo ordine, il numero
complesso
può essere autovalore dell’equazione (necessariamente semplice se i
coefficienti sono reali). In questo caso, dovremo aumentare il grado di
,
ricercando una soluzione particolare di forma
con e
polinomi del
medesimo grado di .
Quando il termine forzante ha forma
oppure ,
con
autovalore dell’equazione, si dice che si presenta il fenomeno della
risonanza e si dice che il termine forzante è risonante
8.3.4 Problema di Cauchy per le equazioni differenziali lineari del secondo
ordine
Ricapitolando, nel caso di un generico termine noto
(e non solo
quando
ha forma particolare) l’integrale generale di (8.17) è
con
integrale particolare dell’equazione completa ed
,
integrali particolari dell’equazione omogenea associata (questi avranno forme
diverse a seconda che gli autovalori siano reali o meno, coincidenti o meno). Il
problema di Cauchy per l’equazione del secondo ordine (8.17) consiste nel
determinarne una soluzione che soddisfa alle ulteriori condizioni di Cauchy
Non è diffcile mostrare
Teorema 176 Sia
continua su .
Il problema di Cauchy ammette soluzione unica qualunque siano ,
ed
e questa soluzione è definita su .
8.3.5 Il comportamento in futuro e la stabilità
Le applicazioni alla fisica delle equazioni differenziali, lineari o meno, richiedono spesso
di poter dedurre informazioni sul comportamento delle soluzioni in futuro, ossia
per ,
senza dover preventivamente risolvere l’equazione.
Noi ci limitiamo a considerare questo problema per le soluzioni dei problemi
di Cauchy |
| (8.25) |
|
| (8.26) |
con coefficienti reali e costanti. Si noti: abbiamo esplicitamente assunto
che il termine affne sia nullo.
Diamo quindi alcune definizioni in forma semplificata, valida solamente
per le equazioni differenziali (8.25) e (8.26).
Ripetiamo che se l’equazione da studiare non fosse lineare a coefficienti costanti, queste
definizioni andrebbero precisate meglio. Le soluzioni della (8.25) sono le
funzioni
Dunque, ricordando che
è reale, si hanno i risultati compendiati nella tabella 8.1.
Table 8.1: Equazioni differenziali del primo ordine omogenee, con coeffciente
reale e costante
Consideriamo ora l’equazione differenziale (8.26) a coefficienti reali. Introduciamo le
notazioni nella tabella 8.2, a sinistra. Ricordiamo infatti che se i coefficienti sono
reali, si ha in ogni caso
Con queste notazioni, le soluzioni (in forma reale) si esprimono come scritto nella
tabella 8.2, a destra mentre i risultati sulla stabilità per l’equazione (8.26),
quando i coefficienti sono reali, si leggono nella tabella 8.3.
Table 8.2: Secondo ordine, coefficienti reali e costanti. Sinistra: notazioni.
Destra: Equazioni del secondo ordine omogenee, soluzioni
Table 8.3: Secondo ordine, coefficienti reali e costanti
(e quindi .
Se gli autovalori sono reali allora ,
)
8.4 Manipolazioni usate nei corsi applicativi
Anche nel contesto delle equazioni differenziali, nei corsi di fisica e di
ingegneria verranno usate delle manipolazioni piuttosto “libere”, che è bene
capire.
Prima di tutto consideriamo un modo veloce per risolvere equazioni a variabili
separabili. La giustificazione di questo metodo è quella che noi abbiamo
illustrato al paragrafo 8.2. Consideriamo quindi l’equazione a variabili
separabili
Come si è visto, per trovarne le soluzioni, basta notare che
ove è
primitiva di .
E dunque
con
primitiva di .
Ora calcoliamo le primitive dei due membri. Il simbolo usato per indicare le primitive
di
è
e pensando di fare la sostituzione
(con
soluzione di cui ancora non conosciamo l’esistenza) si trova
Leggendo il primo e l’ultimo termine si trova che basta uguagliare
e poi sostituire con
la funzione incognita ,
Se uno dimentica che il segno di primitiva è
,
da intendere come un unico simbolo indivisibile, potrebbe
sembrargli che questa formula sia stata ottenuta intendendo
; “moltiplicando
per ” i
due membri dell’equazione differenziale e poi mettendo davanti a tutto il simbolo
,
operazioni prive di senso. Nelle applicazioni, spesso si devono considerare sistemi di
equazioni differenziali. Per esempio, si considera il sistema
L’incognita è la coppia di funzioni ,
dipendente da una variabile
che, come al solito, non si indica esplicitamente. Usando la notazione di Leibniz, la variabile
“nascosta” viene
esplicitamente indicata almeno nel membro sinistro, e il sistema si scrive |
| (8.27) |
A questo punto i fisici dividono un’equazione per l’altra e “semplificano”
,
ottenendo
una sola equazione nell’incognita ,
e con la
che è la variabile indipendente. La spiegazione di questo procedimento
è la seguente: supponiamo di aver trovato una soluzione
del sistema (8.27).
Se accade che
allora, almeno localmente, in un intorno di
, la
funzione
è strettamente monotona e quindi invertibile. La sua funzione inversa
ha
derivata
Si può quindi costruire la funzione composta
e
I valori di
e di
sono correlati da
e quindi (almeno localmente)
è funzione della sola ,
che viene indicata come ,
“nascondendo” .
Quindi
Va tenuto presente però che, a differenza delle pratiche descritte al paragrafo 3.4, questo
procedimento ha senso soltanto in un intorno di un punto assegnato: in generale, un dato
iniziale
per cui
(oppure ,
scambiando
con )
e che il risultato è corretto finché la traiettoria non incontra un punto in cui
si
annulla. Però, non c’è nessun modo di capire se e quando ciò accadrà,
guardando il dato iniziale.
8.5 Alcuni esercizi
- Dire quali delle equazioni differenziali seguenti sono scritte in forma normale,
quali sono a variabili separate e quali sono lineari:
|
|
- Identificare le soluzioni costanti delle equazioni differenziali a variabili
separabili seguenti, e spiegare se esse possono usarsi per studiare la
limitatezza delle altre soluzioni
|
|
E’ possibile avere anche qualche informazione sulla monotonia delle
soluzioni?
- Sapendo che
verifica
calcolarne le derivate prima, seconda e terza per
.
- Si consideri l’equazione differenziale
Sia la soluzione che
verifica . Si vuol sapere
se esitono valori di
tali che questa soluzione verifichi anche
.
Si vuol sapere inoltre se esistono valori di
tali che la
soluzione
verifichi .
- Si determinino i domini massimali delle soluzioni dei
seguenti problemi di Cauchy. L’equazione differenziale è
mentre la condizione di Cauchy è una delle seguenti:
|
|
- Si consideri l’equazione del moto armonico
( indica la
massa e
è la costante elastica). Moltiplicando ambedue i membri per
si trovi la legge di conservazione dell’energia
Si interpretino i due addendi che figurano in quest’uguaglianza.
- Si sappia che una funzione
definita su un intervallo verifica
|
| (8.29) |
Si mostri che la funzione
risolve l’equazione del moto armonico (8.28). Quindi le due equazioni (8.28)
e (8.29) “sono equivalenti” nel senso che hanno le medesime soluzioni. Si noti
però che una è scritta in forma normale e l’altra no.
- Si considerino le funzioni ,
con
parametro reale.
- Si mostri che ciascuna di queste funzioni risolve l’equazione
differenziale .
Si noti che l’equazione differenziale non è definita per ,
ma le soluzioni dell’equazione hanno estensione continua a .
Cosa si nota se si prova ad imporre la condizione di Cauchy
?
- Esistono soluzioni dell’equazione che verificano ?
- () Per
si consideri l’equazione
differenziale .
Si vuol sapere se esistono soluzioni dell’equazione differenziale tali che
oppure
.
- ()
Si vuole un’equazione differenziale soddisfatta da una funzione
che gode di questa proprietà, che deve valere salvo un numero finito di valori
: la
tangente in
al grafico della funzione incontra l’asse delle ascisse in un punto
che deve
verificare ,
con numero
indipendente da
(se
si confronti con l’esercizio 15 del Cap. 3).
- () Per
si consideri l’equazione
differenziale . Si
imponga la condizione
(si noti che il secondo membro non è definito per
.
Si mostri che esiste una soluzione che verifica questa condizione, ma che il suo
dominio di esistenza massimale non è un intervallo aperto.
- Al variare del parametro reale
si studi la stabilità dell’equazione differenziale
.
- Si consideri l’equazione differenziale
con
.
Si mostri che una soluzione particolare è
e si calcoli una soluzione particolare quando
.
- ()
Si considerino l’osservazione 166 e l’esempio 170. Si spieghi
perchè l’argomento nell’osservazione 166 non si applica
al caso dell’esempio 170 (quante soluzioni ha l’equazione
?).
Si usi la spiegazione trovata per costruire una terza soluzione del problema di
Cauchy all’esempio 170.
- ()
Siano
ed
due soluzioni diverse del medesimo problema di Cauchy (8.5), definite sullo stesso
intervallo
.
Calcolando le primitive dei due membri di (8.5), si ha
Usando la proprietà di monotonia del calcolo delle
primitive (esercizio 21 del Capitolo 4) si ottenga per
Si deduca, usando l’esercizio 23 del Capitolo 4, che
con ,
,
.
Si spieghi perché questa disuguaglianza non può valere se il numero
è stato scelto
in modo che sia
e se
e
sono diverse. Ciò mostra che, se valgono le ipotesi del Teorema di
Cauchy, i grafici di due soluzioni diverse non possono intersecarsi,
nemmeno se una delle due soluzioni è costante (caso non considerato
nell’osservazione 166).
- Si xonsideri il problema di Cauchy
,
.
Si mostri che la soluzione è definita per
e se ne studi
il limite per .
Si spieghi la relazione di quanto trovato col Teorema 172.
Capitolo 9
Integrali definiti ed impropri
Erano tali per me queste angustie che sopraggiunta
l’invasione dei Francesi, e nella età di soli 20
anni correndo pericolo della libertà e della vita,
in quelli orribili frangenti dicevo fra me “questo
tuttavia è meno male che lo stare alla scuola”.
Monaldo Leopardi, Autobiografia.
L’integrale è un numero che si associa ad una funzione definita su un intervallo (e
dotata di opportune proprietà). Nel caso che la funzione prenda valori positivi, il
suo integrale definisce l’area della parte di piano compresa tra il grafico e l’asse delle
ascisse.
9.1 La definizione dell’integrale
Sia
una funzione limitata e definita su un intervallo
. Dunque, assumiamo
che esista un numero
tale che per ogni
. Si noti che non
richiediamo che la funzione
prenda valori maggiori o uguali a zero. chiamiamo trapezoide individuato dalla funzione
l’insieme
dei punti
tali che
si veda la figura 9.1, nella quale .
Il trapezoide è la parte di piano tratteggiata.
Vogliamo definire un numero che corrisponda al concetto intuitivo di area del
trapezoide di ,
se prende
valori non negativi; oppure, in generale, alla differenza tra le aree della parte di trapezoide
sopra l’asse delle ascisse e di quella che sta sotto. Per questo, suddividiamo l’intervallo
con un numero finito di
punti equidistanti.
|
|
In questo modo,
Abbiamo cioè costruito una partizione di
di tipo particolare:
abbiamo rappresentato
come unione di intervalli (disgiunti) chiusi a sinistra ed aperti a
destra (salvo l’ultimo che è anche chiuso a destra). Indichiamo con
la
partizione introdotta sopra e chiamiamo finezza della partizione il numero
, che
è la distanza tra due punti consecutivi della partizione. Data la partizione
, indichiamo
con
ed i
numeri
Ricordiamo che la funzione
è limitata: . Dunque,
per ogni indice
si ha:
Associamo ora alla partizione
due numeri,
ed , |
| (9.1) |
Questi numeri rappresentano somme di “aree” di rettangoli, l’area
essendo presa col segno negativo se il rettangolo è sotto l’asse delle
ascisse. La figura 9.2 illustra i rettangoli che si usano per costruire la
quando i punti di
divisione sono i numeri
interi . Si faccia la
figura analoga per .
E’ chiaro che |
| (9.2) |
(la disuguaglianza intermedia segue dal fatto che ciascun addendo di
è minore o uguale all’addendo corrispondente di
). Per
per la proprietà di Dedekind esistono i numeri
Si potrebbe provare che |
| (9.3) |
Più precisamente:
DEfiNIZIONE DI INTEGRALE DI RIEMANN
Sia
una funzione definita su un intervallo
e limitata. Se accade che
il numero
si chiama integrale di Riemann (o semplicemente integrale) di
su ;
e la funzione
si dice integrabile su .
L’integrale di Riemann si chiama anche integrale definito
L’integrale di Riemann di
su si
indica col simbolo
Osservazione 177 Si noti il contrasto tra i termini integrale definito ed
integrale indefinito. Il primo indica un numero mentre il secondo indica
l’insieme di tutte le primitive di .
Usando la definizione, si verifichi che una funzione costantemente uguale a
su
ha integrale
uguale a ,
ossia uguale all’area del rettangolo di base
ed altezza
, se
; all’opposto
dell’area se .
L’integrale
si interpreta come area del trapezoide quando accade che
; come
differenza tra l’area della parte di trapezoide che sta sopra l’asse delle ascisse e
quella che sta sotto altrimenti.
Osservazione 178 (Sulla notazione) La notazione
ha una ragione storica e va presa come unico blocco: non si possono separare
e .
Anzi, sarebbe anche lecito scrivere semplicemente
invece di .
Il simbolo più complesso aiuta a ricordare certe formule che vedremo, sia in
questo che in corsi successivi. Inoltre, sottolineiamo che
è un numero. La “variabile”
non ha alcun ruolo e si chiama la variabile muta d’integrazione “Muta” nel
senso che il simbolo prescelto per essa non influisce sul valore dell’integrale, e
può essere cambiato a piacere. Quindi,
E’ però importante capire subito un uso della variabile muta d’integrazione e
del simbolo .
Talvolta si ha una famiglia di funzioni ,
una funzione di
per ogni valore del parametro .
Può essere necessario integrare ciascuna di queste funzioni, ottenendo un
numero per ogni valore di ;
ossia ottenendo una funzione della variabile :
E’ la presenza della notazione
che ci dice quale è la variabile muta d’integrazione e quale è il parametro.
Esempio 179 Quest’esempio mostra la debolezza della definizione che
abbiamo scelto: per calcolare
basta usare un solo rettangolo. Non c’è nessun bisogno di suddividere
il trapezoide in “tanti” rettangoli. Ciò fa capire che dovendo calcolare
numericamente l’integrale di una funzione il cui grafico è quello in figura 9.3,
a sinistra, converrà usare una partizione non uniforme dell’intervallo ,
mettendo pochi punti di suddivisione dove la funzione è circa costante
e tanti punti dove varia velocemente. La figura 9.3, a destra, mostra
che un metodo ancora più effciente consiste nell’approssimare l’area da
calcolare mediante trapezi, invece che mediante rettangoli. Nella figura a
destra abbiamo disegnato i trapezi usando meno punti di suddivisione
di quanti ne avessimo usati per i rettangoli per non confondere il lato
del trapezio col grafico della funzione; e ciò nonostante è evidente che
l’approssimazione mediante “pochi” trapezi è migliore di quella con “tanti”
rettangoli.
Una definizione più generale. L’esempio 179 mostra l’utilità per il calcolo
numerico di approssimare il valore dell’integrale mediante partizioni dell’intervallo
ottenute
con punti non equidistanti. Si potrà quindi cercare di ripetere la costruzione
dell’integrale usando partizioni con punti non equidistanti, costruendo le somme
ed
con formule analoghe
a quelle delle
ed e
mandando a zero la finezza della partizione, ossia la massima delle distanze tra i
punti consecutivi della partizione. Potrebbe venire il dubbio che in questo modo
si ottenga un numero diverso da quello che si trova mediante partizioni
con punti equidistanti. Senza indugiare a provarlo, diciamo che ciò non
accade.
9.1.1 Proprietà dell’integrale
Le proprietà cruciali dell’integrale sono la linearità, la monotonia e
l’additività.
Linearità dell’integrale. In generale si chiama “lineare” una
trasformazione che si distribuisce sulla somma e da cui “si portano
fuori” le costanti moltiplicative; ossia una trasformazione, diciamo
, con
questa proprietà:
L’integrale di Riemann ha questa proprietà. Infatti, vale:
Teorema 180 Siano
e
due funzioni integrabili sul medesimo intervallo
e siano
e
due numeri reali. In tal caso la funzione
è integrabile su
e inoltre vale
La dimostrazione non è diffcile ma un po’ macchinosa. Questa proprietà si chiama
linearità dell’integrale Ricordiamo che
da cui
Si potrebbe provare:
Teorema 181 La funzione ,
limitata su ,
è integrabile se e solo se sono integrabili ambedue le funzioni
ed .
Ciò combinato con la proprietà di linearità dell’integrale dà:
Teorema 182 Se
è integrabile su
allora è
integrabile su .
Inoltre, valgono le uguaglianze |
|
Monotonia dell’integrale. E’ pressoché immediato dalla definizione di
integrale:
Teorema 183 Sia
integrabile e positiva. Allora,
Sia ora
Usando la linearità si vede che
Dunque:
Corollario 184 Se
e
sono integrabili sul medesimo intervallo
e se
per ogni ,
allora si ha
Questa proprietà si chiama monotonia dell’integrale Usando l’integrabilità del valore
assoluto (Teorema 182) e la disuguaglianza
si trova
Additività dell’integrale. Sia
definita su
e sia .
Vale
Teorema 185 La funzione
è integrabile su
se e solo se è integrabile sia su
che su
e in tal caso si ha
Questa proprietà si chiama additività dell’integrale Grazie
a questo teorema, possiamo definire la funzione integrale di
. Sia
integrabile
su . Per
ogni
calcoliamo la funzione
Poniamo inoltre
cosìche è
definita su . La
funzione si chiama la
funzione integrale di .
Integrale ed operazioni. La proprietà di linearità mostra
le relazioni tra le operazioni di somma e di moltiplicazione per
costanti e il calcolo dell’integrale. Il Teorema 182 mostra che se
è integrabile
allora ,
e
sono integrabili, senza dare modo di calcolarne l’integrale. Vale anche:
Teorema 186 Si ha:
- se
e
sono integrabili su
anche
è integrabile su ;
- se
e
sono integrabili su
e inoltre se
è continua e non si annulla su ,
allora anche
è integrabile su .
Va detto però che non c’è alcuna relazione semplice tra gli integrali di due
funzioni e quello del loro prodotto o del loro quoziente.
9.1.2 Classi di funzioni integrabili
Valgono i due teoremi seguenti:
Teorema 187 Se
è continua sull’intervallo limitato e chiuso ,
essa è integrabile su
e quindi su ciascun suo sottointervallo.
Teorema 188 Se
è monotona sull’intervallo limitato e chiuso ,
essa è integrabile su
e quindi su ciascun suo sottointervallo.
Combinando questi teoremi con la proprietà di additività dell’integrale, segue che se
l’intervallo
è unione di due o più sottointervalli su ciascuno dei quali la
funzione ha restrizione continua oppure monotona, allora la funzione
è integrabile su
. Dimostrazione
del Teorema 188. Supponiamo per fissare le idee che la funzione sia crescente su
. Notiamo che la
funzione è limitata su .
Infatti vale
Suddividiamo l’intervallo
in parti
uguali e
consideriamo le somme (9.1), ossia |
|
cosìche
Ricordiamo che l’integrale esiste se
e che in generale (si veda la (9.3)):
Dobbiamo quindi provare che la differenza
non è strettamente
positiva. Ossia, dobbiamo
provare che per ogni
vale
Notiamo che
Dunque, basta provare che per ogni
esiste un opportuno
tale che
Si ricordi che l’intervallo
si è diviso in
parti uguali, ossia .
Dunque si ha |
|
Queste relazioni valgono per ogni .
fissato
esiste
tale che
e quindi vale
come volevamo.
9.1.3 La media integrale
Sia
integrabile su
e sia
Consideriamo le due funzioni
cosìche
La monotonia dell’integrale mostra che
ossia esiste
tale che:
Il numero
è ovviamente definito da
La sua proprietà essenziale è di essere compreso tra
e
. Il numero
si chiama la
media integrale di .
Sia ora
continua su .
Ricordando il teorema dei valori intermedi si ha:
Teorema 189 Se
è continua su ,
la sua media integrale è uno dei valori della funzione; ossia esiste
tale che
Se ,
il significato del numero ,
media integrale di
su ,
è il seguente: il numero
è l’altezza del rettangolo di base
,
la cui area è uguale a quella del trapezoide. Ciò è illustrato in
figura 9.4. La figura mostra anche la bisettrice del primo quadrante che non
ha alcun ruolo nella media integrale. E’ disegnata solo per sottolineare il fatto
che l’unità di misura è la medesima sui due assi.
9.2 Integrale orientato
Nel simbolo dell’integrale di Riemann
necessariamente .
Vogliamo ora definire questo simbolo anche nel caso
. Ciò
si fa semplicemente ponendo
Uno dei due membri è definito e l’uguaglianza definisce l’altro. Si noti che se
si
trova
L’integrale
cosìintrodotto, senza che debba essere
, si
chiama integrale orientato Per esso valgono tutte le proprietà viste per l’integrale
di Riemann, salvo la monotonia che richiede un po’ di cautela, perché le
disuguaglianze cambiano verso quando si cambia segno ai due membri.
Quindi:
la disuguaglianza
NON VALE PER L’INTEGRALE ORIENTATO perché il secondo
membro può essere negativo ed il primo positivo. Essa va sostituita
da
Invece, la definizione della media integrale rimane la stessa anche
per l’integrale orientato: la media integrale sull’intervallo di estremi
ed
è
e tale numero è compreso tra l’estremo inferiore e l’estremo
superiore dei valori che la funzione prende sull’intervallo di estremi
ed ,
sia quando
che quando .
Invece, per l’integrale orientato vale la proprietà di additività
senza alcun vincolo sull’ordine dei tre numeri
,
e
.
Usando ciò, si può definire la funzione integrale
sia per che per
(ovviamente,
se è definita ).
Infatti
In particolare,
Teorema 190 Se
è definita su
e positiva, la funzione
è crescente su .
9.3 La funzione integrale
Ricordiamo che se
è integrabile su
essa è integrabile su ogni sottointervallo. In particolare è integrabile su
e quindi possiamo definire la funzione integrale di
, ossia
la funzione
Se accade che la funzione è
definita anche a sinistra di ,
la funzione integrale si definisce anche a sinistra di
,
facendo intervenire l’integrale orientato:
Se la funzione
ha segno costante, la funzione integrale è monotona:
Teorema 191 Se
è positiva la funzione integrale è crescente mentre se
è negativa allora la funzione integrale è decrescente.
Dim. Proviamo la crescenza, supponendo che
sia positiva. Sia
e proviamo che
. Ciò è ovvio se
perché in tal caso
. Quindi consideriamo
i due casi
ed :
-
- caso :
usando l’additività dell’integrale si ha
perché .
-
- caso : la
definizione di integrale orientato e l’additività dell’integrale danno
|
|
perché e quindi
.
Proviamo il lemma seguente:
Lemma 192 Sia
integrabile su
e sia .
Si ha:
(se
allora
mentre se
allora ).
Dim. Ricordiamo che una funzione integrabile è per definizione limitata:
Dunque si ha
L’asserto segue dal teorema di confronto dei
limiti.
Conseguenza di questo risultato è che la funzione integrale è continua anche
se
può non essere continua:
Teorema 193 La funzione
è continua su .
Dim. Va provato:
(se
oppure
allora
oppure ).
L’additività dell’integrale permette di scrivere |
|
per il Lemma 192, come si voleva.
Proviamo ora:
Lemma 194 Sia
continua in .
Allora,
Dim. Va provato che per ogni
esiste tale
che se
si ha |
| (9.4) |
Usando la continuità di
in si trova:
per ogni
esiste tale
che se
si ha:
Scegliamo con
. La monotonia
dell’integrale dà (sia se
che se ,
usando la definizione di integrale orientato):
ossia, se
si ha
che è quanto volevamo provare.
Se
è una funzione integrabile qualsiasi, la funzione
può non essere
derivabile. Invece, se
è continua la funzione
è derivabile:
Teorema 195 (Teorema fondamentale del calcolo integrale) Se
è continua su ,
la funzione
è derivabile su
e vale
Ossia, la funzione integrale di una funzione continua
ammette
derivata in ogni
punto di , ed
è la funzione
integranda .
Di conseguenza,
Corollario 196 Ogni funzione continua su un intervallo ammette primitive.
Dimostrazione del Teorema 195. La funzione
è continua
su
e quindi il Lemma 194 può applicarsi in ciascun punto di
. Dunque,
per ogni
si ha: |
|
(intendendo che indica la derivata
destra se e la derivata sinistra se
).
L’importanza pratica di questo risultato sta nel fatto che, se
è
continua, il calcolo dell’integrale definito può ottenersi tramite il calcolo delle primitive.
Ossia, la ,
funzione integrale, è una particolare primitiva di
: è quella primitiva
che si annulla in .
Ricordiamo ora che due primitive diverse su un intervallo
di
una medesima funzione hanno differenza costante. Quindi, se mediante le
tecniche di calcolo delle primitive, si è trovata una qualsiasi primitiva
della funzione
continua ,
si ha:
Lo scarto
si indica anche col simbolo
e quindi si scrive
9.3.1 Integrazione per sostituzione
Il teorema fondamentale del calcolo integrale permette di correlare integrali
calcolati mediante trasformazioni del dominio di integrazione. Sia
continua
su e
sia
una sua primitiva. Come si è visto, |
| (9.5) |
Sia una funzione
continua su un intervallo
e derivabile su .
Supponiamo inoltre che .
Quindi esistono punti
e in
tali
che
E’
e quindi
Ma,
e quindi si ha anche
ossia |
| (9.6) |
Si noti che questa formula vale in generale per l’integrale orientato. Anzi,
anche se l’integrale a sinistra di (9.6) è un’integrale di Riemann, può ben
essere che gli estremi dell’integrale di destra coincidano o anche che sia
.
Osservazione 197
Se l’integrale da calcolare è (9.5) allora dovremo identificare un intervallo
ed una trasformazione
tale che
e
(o viceversa) e tale che l’integrale a sinistra in (9.6) sia più facile
da calcolare di quello a destra. Non abbiamo richiesto che la funzione
sia iniettiva. Se lo è allora la formula (9.6) si può scrivere nella forma
9.4 Integrale improprio
Si chiama integrale improprio quello che si ottiene estendendo l’integrale di
Riemann a funzioni dotate di asintoto verticale oppure definite su una semiretta (o
ambedue le cose) mediante il calcolo di un limite. Conviene vedere separatamente i
due casi seguenti, che verranno poi combinati insieme. Introduciamo un termine: sia
definita su
un intervallo ,
limitato o meno. Non si richiede che la funzione sia limitata. La funzione
si dice localmente integrabile quando è integrabile (nel
senso di Riemann e quindi anche limitata) su ogni intervallo
limitato e chiuso
contenuto in .
9.4.1 L’integrale su una semiretta
Consideriamo una funzione
definita sulla semiretta
ed integrabile (nel senso di Riemann e quindi limitata) su ogni intervallo
. E’
cosìpossibile definire la funzione
Consideriamo
Se questo limite esiste, finito o meno, si definisce
e si chiama integrale improprio (su )
di . Si
hanno i casi elencati nella tabella 9.1
Table 9.1: I casi dell’integrale improprio
9.4.2 L’integrale in presenza di un asintoto verticale
Supponiamo che la funzione
sia definita su ed abbia
asintoto verticale :
Supponiamo inoltre che sia localmente integrabile su
. In
questo caso, si può definire la funzione
per ogni e si può
studiarne il limite per .
Se questo limite esiste lo indicheremo col simbolo
e lo chiameremo ancora integrale improprio su
.
Se il limite è finito diremo che l’integrale improprio converge; se è
oppure
diremo
che diverge. Se il limite non esiste, diremo che l’integrale improprio non esiste
(equivalentemente, oscilla o è indeterminato). Ossia, per l’integrale improprio su
si
può fare una tabella analoga alla 9.1.
9.4.3 Casi più generali
I due casi precedenti possono combinarsi tra loro. Per esempio:
- se
è localmente integrabile su ,
si possono studiare i due limiti
con lo stesso .
Usando l’additività dell’integrale, si mostra che se i due limiti esistono
finiti o infiniti di segno concorde la loro somma non dipende dalla
scelta di
e si scrive
- in modo analogo si procede se la funzione ha più asintoti verticali;
- in modo analogo, se
è localmente integrabile su ,
scriveremo
(i limiti devono essere finiti o infiniti di segno concorde). E’ importante
sottolineare che i due limiti, per
e per ,
vanno calcolati indipendentemente. Per esempio, la funzione
non ha integrale improprio su
perché i due limiti precedenti sono il primo
e il secondo .
Però,
perché la funzione è dispari e quindi
per ogni .
9.5 Criteri di convergenza per integrali impropri
In pratica, il calcolo di un integrale improprio è diffcile e non si riesce a fare
esplicitamente. Si danno però dei criteri che assicurano la convergenza o
divergenza dell’integrale, che conviene esaminare prima nel caso di funzioni
positive.
9.5.1 Criteri di convergenza: funzioni positive su semirette
Per fissare le idee, supponiamo di lavorare su una semiretta verso destra,
e di avere una funzione che prende valori maggiori o uguali
a zero e che è integrabile su ogni intervallo limitato
.
Consideriamo la funzione
Questa è una funzione crescente di
perché
la è
positiva. Quindi, per il teorema delle funzioni monotone,
esiste, finito o meno. Dunque,
Teorema 198 Se la funzione
prende valori maggiori o uguali a zero, l’integrale improprio
converge oppure diverge. Esso non può essere oscillante.
Quindi, se possiamo dire che esiste
tale che
per ogni
allora l’integrale converge; se invece la funzione di
è minorata da una
funzione divergente a ,
l’integrale improprio diverge. Quest’osservazione si usa confrontando la funzione
con
funzioni di “forma più semplice” il cui integrale si sa calcolare. Infatti:
Teorema 199 (di confronto per gli integrali impropri) Siano
e
localmente integrabili su .
Valga inoltre
Allora: |
|
Siamo quindi ridotti a cercare delle funzioni di confronto
abbastanza semplici. Ricordando che gli infinitesimi fondamentali di confronto per
sono
le funzioni
è naturale confrontare con queste funzioni, i cui integrali si calcolano
facilmente:
Dunque, si ha la situazione riassunta nella tabella 9.2.
Table 9.2: integrali impropri su una semiretta
Inoltre,
Teorema 200 la funzione
(non negativa) abbia parte principale
per .
I due integrali impropri di
e di
hanno lo stesso comportamento.
Dim. Infatti, l’ipotesi implica che
e inoltre
e quindi in particolare, per
abbastanza grande, vale
Si noti che la condizione
si verifica in particolare se è
(positiva ed) un infinitesimo per ,
di ordine maggiore di .
Dunque,
Teorema 201 Se
ed inoltre per
la funzione
è un infinitesimo di ordine maggiore di
con ,
ossia
allora l’integrale improprio
è convergente.
E’ importante notare che nell’enunciato precedente la condizione
è cruciale. La condizione che
sia infinitesima di ordine maggiore ad
,
con esponente esattamente ,
non implica la convergenza dell’integrale. Per esempio,
ma una primitiva di
è
e quindi
9.5.2 Criteri di convergenza: funzioni positive su intervalli
Consideriamo il caso in cui
su , con asintoto
verticale .
In questo caso, la funzione
è decrescente e quindi dotata di limite per
, finito
o meno. E quindi si può ancora enunciare il teorema del confronto, come segue:
Teorema 202 (di confronto per gli integrali impropri) Siano
e
localmente integrabili su .
Valga inoltre
Allora: |
|
Naturalmente, è ancora naturale scegliere come funzione di confronto gli infiniti campione
. Vale
anche in questo caso
Teorema 203 la funzione
(non negativa) abbia parte principale
per .
I due integrali impropri di
e di
hanno lo stesso comportamento.
Quindi, va capito quando diverge oppure converge l’integrale improprio di
.
E’ ancora vero che l’integrale improprio è divergente se
, però ora le
due condizioni
e
hanno ruolo scambiato:
Quindi, si può ancora dare una tavola analoga alla 9.2, ma con
versi delle disuguaglianze scambiate. Si veda la tabella 9.3 (dove
e si intende che
è integrabile nel
senso di Riemann su
per ogni ).
Table 9.3: integrali impropri su un intervallo
Si noti che la condizione
si verifica in particolare se è
(positiva ed) un infinito per ,
di ordine inferiore ad .
Dunque,
Teorema 204 Se
ed inoltre per
la funzione
è un infinito di ordine inferiore ad
con ,
ossia
allora l’integrale improprio
è convergente.
Ripetiamo ancora che se
è un infinito di ordine inferiore esattamente ad
(ossia se nell’enunciato
precedente si ha )
niente può affermarsi dell’integrale improprio di
.
9.5.3 Il caso delle funzioni che cambiano segno
Ricordiamo le notazioni
cosìche
Dunque, se
ha integrale improprio convergente, anche le due funzioni
e
hanno integrale improprio convergente. E quindi la loro somma
ha
integrale improprio convergente. Si può quindi enunciare
Teorema 205 Una funzione localmente integrabile il cui valore assoluto
ha integrale improprio convergente, ha essa stessa integrale improprio
convergente.
E si noti che quest’asserto vale sia su semirette che su intervalli. In sostanza, questo è
l’unico criterio (ovviamente solo suffciente) di cui disponiamo per provare che una
funzione di segno variabile ha integrale improprio convergente: si prova che è
assolutamente integrabile (ossia che il suo valore assoluto è integrabile) usando i
criteri noti per le funzioni di segno costante. Se ne deduce che l’integrale improprio
della funzione converge.
9.6 Alcuni esercizi
- Si traccino i grafici delle funzioni
|
|
e si calcolino gli integrali su
dei loro prodotti.
- Sia integrabile
su e dispari.
Si mostri che .
- Trovare una funzione pari e non nulla, tale che
, con
.
- ()
Se esiste, si trovi un esempio di funzione integrabile
, definita
su , con
. Può
essere che
sia continua? (Si ricordi il teorema di permanenza del segno).
- Sia
continua su ,
con per
. Mostrare
che
ha integrale strettamente positivo su qualsiasi intervallo.
- Sia dispari e
continua su .
Mostrare che .
- Sia
integrabile su
e non negativa. Si mostri che
E se
è negativa?
- () Si provi che
se è positiva
su e localmente
integrabile e
crescente, allora
è crescente. Esaminare cosa può dirsi se
è decrescente, e cosa può dirsi di
- I due problemi seguenti sono formulazioni diverse dello stesso fatto:
- sia .
Calcolare
- sia
continua per .
Mostrare che per ogni
si ha
(è possibile che, con
non nulla, valga l’uguaglianza per un opportuno ?
E per ogni ?)
Sia .
Mostrare che la disuguaglianza precedente vale anche se
intendendo l’integrale come integrale orientato.
- () Sia
monotona
crescente su .
Mostrare che esiste il limite
Il limite può essere nullo?
- La funzione
sia positiva, con integrale improprio convergente su
. Si chiede di sapere
se può essere .
- () La
funzione
sia positiva, con integrale improprio convergente su
. Si chiede di sapere
se deve essere .
- ()
Sia
Si disegni il grafico di
e (usando la formula (1.6)) si calcoli
- ()
Si dica se esiste una funzione continua e positiva, con integrale improprio finito su
, ma priva di
limite per .
- Sia
(
finito o meno). Calcolare
- Sia
una funzione per la quale converge l’integrale improprio
Mostrare che
per ogni .
Cosa può dirsi se l’integrale improprio diverge oppure oscilla?
- Si mostri che .
Spiegare come si trasforma questa formula se l’integrale è sull’intervallo
con
(incluso
il caso ,
supponendo la convergenza degli integrali impropri).
- () Si
considerino le funzioni definite all’esercizio 26 del Cap. 2, ossia le funzioni definite
su
da
Si calcoli
e si consideri la successione di numeri
.
Se ne calcoli il limite e si rifletta sulla relazione, o mancanza di
relazione, che intercorre tra questa successione e il limite di
, per
ogni ,
calcolato all’esercizio 26 del Cap. 2.
- ()
Una sbarretta di densità variabile è distesa sull’intervallo
dell’asse
. Sia
la densità del
punto di ascissa .
In fisica, si definiscono massa e centro di massa della sbarra i due numeri
seguenti:
Si provi che se
vale
- Sia
e sia
Usando la formula di L’Hospital si provi che
ossia: il centro di massa di un segmento
tende
ad
quando la lunghezza del segmento tende a
.
Appendix A
Glossario
- Limitazione superiore di un insieme significa “maggiorante”; per dire
“minorante” si dice anche limitazione inferiore
- Le notazioni seguenti si equivalgono:
Analogamente, si equivalgono
In particolare si potrà scrivere:
- La notazione
indica la successione .
Il simbolo
può indicare sia la successione
che l’insieme degli elementi ,
ossia l’immagine della successione. Talvolta una successione si indica col
simbolo ,
senza parentesi, cosìcome si scrive
per indicare la funzione .
- Abbiamo notato che le definizioni di limite si formulano in modo
unificato se si usa il linguaggio degli intorni. Però noi abbiamo preferito
specificare
“
con
oppure
oppure ”.
Si può abbreviare questa frase introducendo la notazione ,
ove
indica l’unione di
e dei due simboli
e .
In questo modo, la frase tra virgolette viene compendiata dalla scrittura
.
Invece di
si usa anche il simbolo .
- Successione indeterminata o successione oscillante è una successione
priva di limite (per ).
Si noti che invece soluzione oscillante di un’equazione differenziale indica
una soluzione con infiniti cambiamenti di segno, anche se dotata di
limite, come per esempio .
- Funzione indeterminata (per )
si usa per dire che
non esiste.
- Il punto
si dice
- punto estremale,
- punto critico,
- punto singolare,
- punto stazionario,
- punto di stazionarietà
per una funzione
se è un punto interno al dominio di
, la
è
derivabile in
e si ha .
I punti di massimo e di minimo (locali o globali) di
si chiamano anche “estremi globali” o “estremi locali” della funzione. Fare
ben attenzione a non confonderli con gli estremi dell’immagine della
funzione!
- Si equivalgono i termini integrale definito ed integrale di Riemann.
- Sia
un intervallo, limitato o meno. Una funzione si dice localmente integrabile su
quando
è integrabile (nel senso dell’integrazione di Riemann) su ogni intervallo limitato e chiuso
contenuto
in .
- Un integrale improprio si dice indeterminato quando non esiste il limite mediante
il quale esso è definito; ossia, se per esempio l’integrale improprio da considerare
è ,
quest’integrale è indeterminato quando il limite non esiste.
- Per indicare l’insieme delle primitive, invece di
si può anche scrivere
Per indicare l’integrale definito, invece di
si può anche scrivere
Simboli analoghi possono usarsi anche per gli integrali impropri.
|